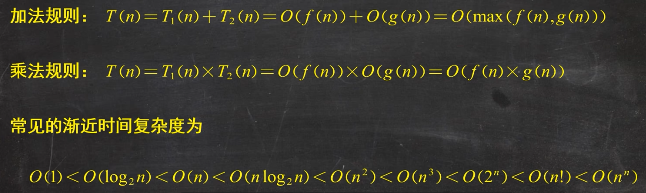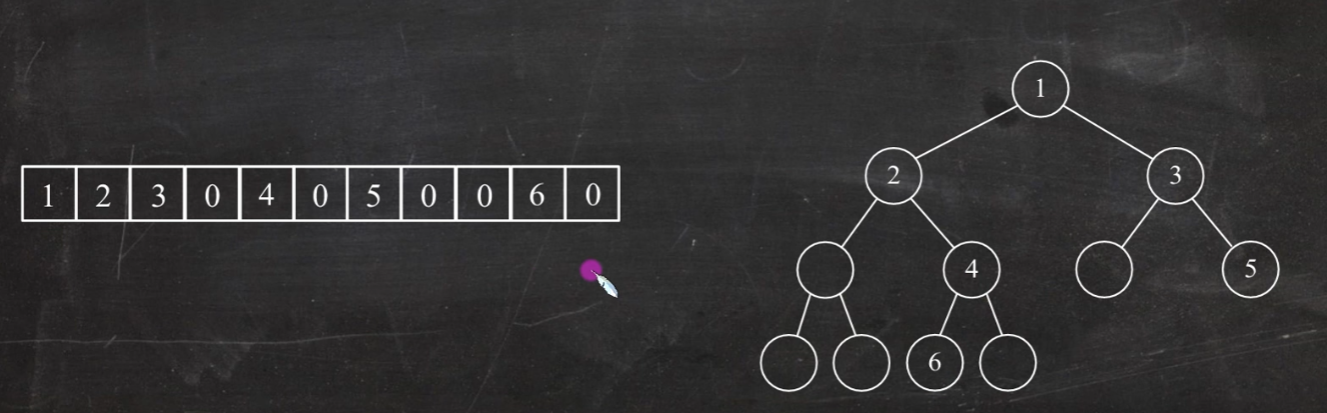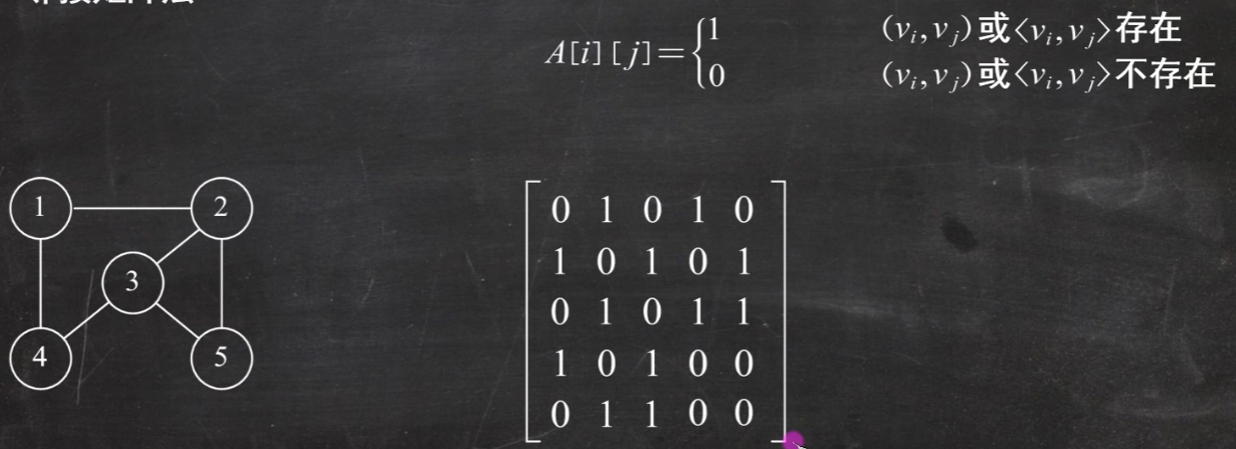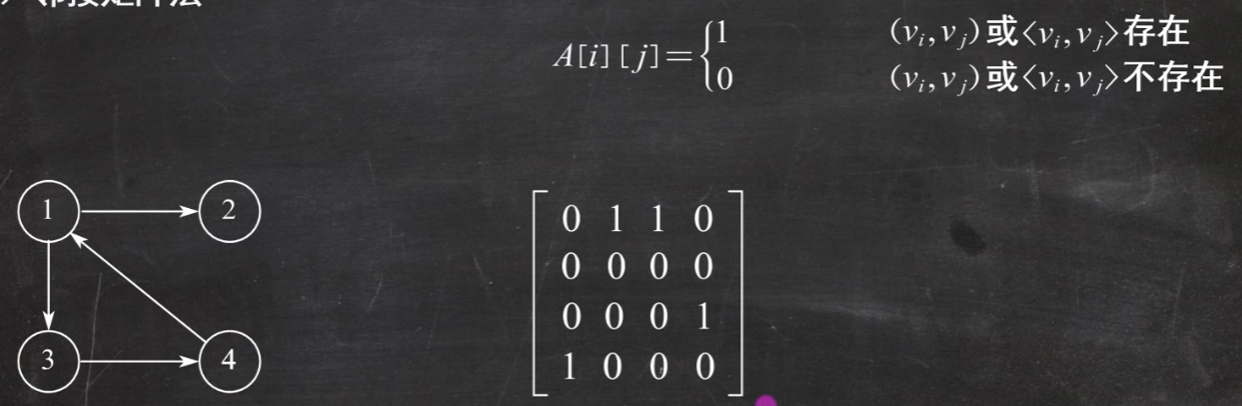cppu版,老师讲的比较简单,所以很简略
1.数据结构 数据:对客观事物的符号表示:图像、声音等数据元素有限集、数据关系有限集 ,注意对应
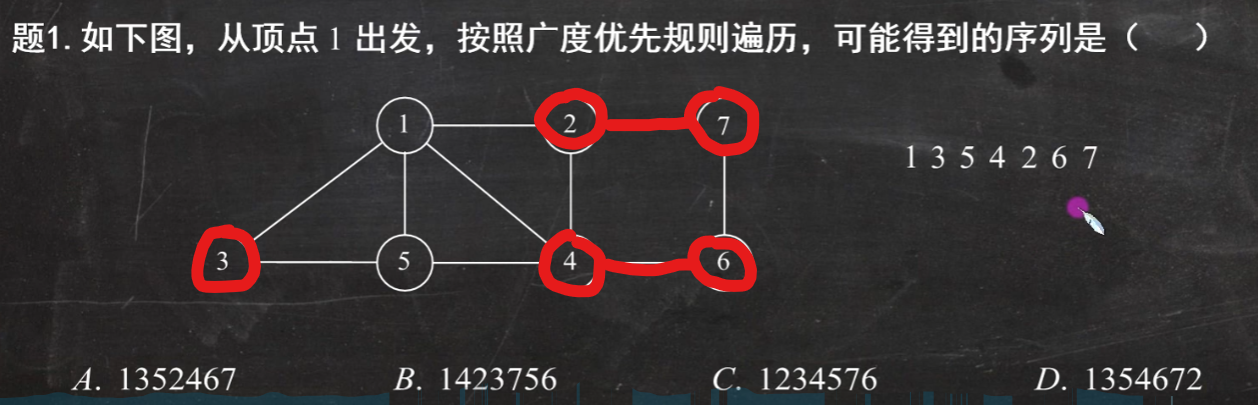
题1.以下说法正确的是()
逻辑结构分为线性结构(线性表(栈、队列、串、数组)(一对多))、非线性结构(集合、树形结构(一对多)、图形结构或网状结构(多对多))
存储结构(物理结构):顺序存储(逻辑上和物理上位置一致)、链式存储(借助指示元素存储地址的指针) 、索引存储(索引表:索引项(关键字、地址))、散列存储(哈希存储)(关键字通过散列函数到存储地址)
2.算法 有穷性(有穷步骤和时间)、确定性、可行性、输入、输出
目标:正确性、可读性、健壮性、效率与低存储量需求
时间复杂度只保留频度之和的数量级
3.顺序表 ①线性表:具有相同数据类型的n个数据元素的有限序列
实训代码 题目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 本关任务:对于顺序存储的线性表完成两个操作函数,分别实现顺序表中数据的插入、删除功能。 相关知识 实训中的类型定义及子函数的作用如下: (1)定义顺序表类型SqList; #define MAXSIZE 100 //顺序表可能达到的最大长度 typedef int ElemType; //假设顺序表中所有元素为int类型 typedef struct { ElemType *elem; //指向数据元素的基地址 int length; //顺序表的当前长度 } SqList; (2)子函数InitList(SqList &L),实现顺序表的初始化; (3)子函数CreateList(SqList &L),实现顺序表的创建,从键盘上依次输入整型数据元素,创建顺序表; (4)子函数ListInsert(SqList &L,int i ,ElemType e),实现顺序表中的插入运算; (5)子函数 ListDelete(SqList &L,int i),实现顺序表中的删除运算; (6)子函数PrintList(SqList L),实现顺序表的打印输出。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <iostream> using namespace std;#define MAXSIZE 100 typedef int ElemType; typedef struct { ElemType *elem; int length; } SqList; void InitList (SqList &L) new ElemType[MAXSIZE]; if (!L.elem) exit (-2 ); L.length=0 ; } void CreateList (SqList &L) int i,n; cin>>n; for (i=0 ;i<n;i++) { cin>>L.elem[i];} L.length=n; } int ListInsert (SqList &L,int i,ElemType e) if (i<1 or i>L.length+1 )return 0 ; for (int j=L.length-1 ;j>=i-1 ;j--){ L.elem[j+1 ]=L.elem[j]; } L.elem[i-1 ]=e; ++L.length; return 1 ; } int ListDelete (SqList &L,int i) if (i<1 or i>L.length+1 )return 0 ; for (int j=i-1 ;j<L.length;j++){ L.elem[j]=L.elem[j+1 ]; } --L.length; return 1 ; } void PrintList (SqList L) int i; for (i=0 ;i<L.length;i++) cout<<L.elem[i]<<" " ; cout<<endl; } int main () int r,k; SqList L; InitList (L); CreateList (L); r=ListInsert (L,5 ,6 ); if (r) PrintList (L); else cout<<"插入位置非法" <<endl; k=ListDelete (L,3 ); if (k) PrintList (L); else cout<<"删除位置非法" <<endl; return 0 ;}
题目2
1 本关任务:对于无序的顺序表,可能存在着一些值相同的“多余”数据元素(类型为整型),编写一个程序将“多余”的数据元素从顺序表中删除,使该表由一个“非纯表”(值相同的元素在表中可能有多个)变成一个“纯表”(值相同的元素在表中只保留第一个)。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <iostream> using namespace std;#define MAXSIZE 100 typedef int ElemType; typedef struct { ElemType *elem; int length; } SqList; void InitList (SqList &L) new ElemType[MAXSIZE]; if (!L.elem) exit (-2 ); L.length=0 ; } void CreateList (SqList &L) int i,n; cin>>n; for (i=0 ;i<n;i++) { cin>>L.elem[i];} L.length=n; } void DeleteList (SqList &L) int newlen=0 ; for (int i=0 ;i<L.length;i++) { bool ischongfu=false ; for (int j=0 ;j<newlen;j++) { if (L.elem[i]==L.elem[j]) { ischongfu=true ; break ; } } if (!ischongfu) { L.elem[newlen]=L.elem[i]; newlen++; } } L.length=newlen; } void PrintList (SqList L) int i; for (i=0 ;i<L.length;i++) cout<<L.elem[i]<<" " ; cout<<endl; } int main () SqList a; InitList (a); CreateList (a); DeleteList (a); PrintList (a); }
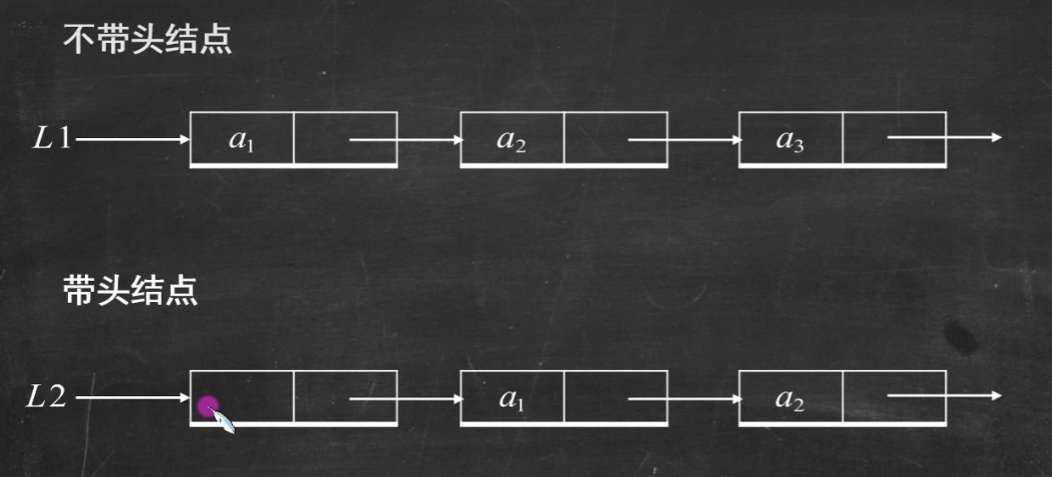
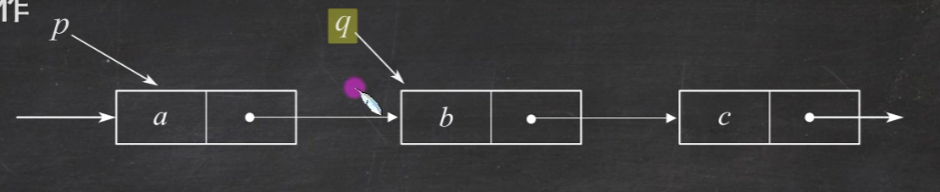
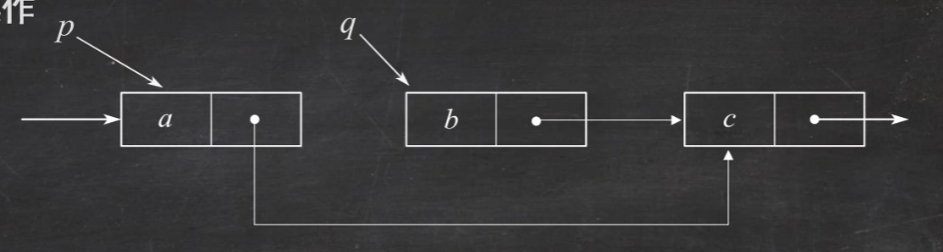
4.链表 链式存储的线性表
1 2 3 4 typedef struct LNode{ Elemtype data; struct LNode *next; }LNode,*Linklist; //前者强调结点,后者强调链表
结构有带头结点和不带头结点的
单链表的实现 实训1代码 题目:
1 2 3 4 5 6 7 8 9 10 11 12 本关任务:对于链式存储的线性表完成三个操作函数,分别实现单链表的创建、数据的插入、删除功能。 实训中的类型定义及子函数的作用如下: (1)定义单链表类型; typedef struct LNode{ ElemType data; //结点的数据域 struct LNode *next; //结点的指针域 }LNode,*LinkList; (2)子函数InitList(LinkList &L),实现单链表的初始化; (3)子函数CreateList(LinkList &L,int n),实现单链表的创建; (4)子函数ListInsert(LinkList &L,int i,ElemType e),实现单链表中的插入运算; (5)子函数 ListDelete(LinkList &L,int i,ElemType &e),实现单链表中的删除运算; (6)子函数PrintList(LinkList L),实现单链表的打印输出。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 #include <iostream> using namespace std;#define OK 1 #define ERROR 0 typedef int Status;typedef int ElemType; struct LNode { ElemType data; struct LNode *next; }; typedef struct LNode *LinkList; void InitList (LinkList &L) L=new LNode; L->next=NULL ; } void CreateList (LinkList &L,int n) L=new LNode; L->next=NULL ; for (int i=n;i>0 ;--i) { LinkList p=new LNode; cin>>p->data; p->next=L->next; L->next=p; } } int ListInsert (LinkList &L,int i,ElemType e) LinkList p=L;int j=0 ; while (p and j<i-1 ){p=p->next;++j;} if (!p or j>i-1 )return 0 ; LinkList s=new LNode; s->data=e; s->next=p->next; p->next=s; return 1 ; } int ListDelete (LinkList &L,int i) LinkList p=L;int j=0 ; while (p->next and j<i-1 ) { p=p->next; ++j; } if (!(p->next) or j>i-1 )return 0 ; LinkList q=p->next; p->next=q->next; LinkList data,e; delete q; return 1 ; } void PrintList (LinkList &L) LinkList p=L->next; while (p) { cout<<p->data<<" " ; p=p->next; } cout<<endl; } int main () int n,i,j,e,l; LinkList L; cin>>n; InitList (L); CreateList (L,n); PrintList (L); cin>>i; cin>>e; j=ListInsert (L,i,e); if (j) PrintList (L); else cout<<"插入位置非法" ; cin>>i; j=ListDelete (L,i); if (j) PrintList (L); else cout<<"删除位置非法" <<endl; return 0 ; }
实训题目2 题目:
1 2 3 4 本关任务:编写一个程序,实现带头结点的单链表的逆置。 为了完成本关任务,你需要掌握: 1.单链表中头插法的实现过程, 2.单链表中指针的修改。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 #include <iostream> using namespace std;#define OK 1 #define ERROR 0 typedef int Status;typedef int ElemType; struct LNode { ElemType data; struct LNode *next; }; typedef struct LNode *LinkList; void InitList (LinkList &L) L=new LNode; L->next=NULL ; } void CreateList (LinkList &L,int n) int i; LinkList p; L=new LNode; L->next=NULL ; for (i=n;i>0 ;--i) { p=new LNode; cin>>p->data; p->next=L->next; L->next=p; } } void ReverseList (LinkList &L) LinkList p; p=L->next; L->next=NULL ; while (p) { LinkList q=p; p=p->next; q->next=L->next; L->next=q; } } void PrintList (LinkList &L) LinkList p=L->next; while (p) { cout<<p->data<<" " ; p=p->next; } cout<<endl; } int main () LinkList a; InitList (a); int n; cin>>n; CreateList (a,n); ReverseList (a); PrintList (a); }
按序号查找结点值O(n) 1 2 3 4 5 6 7 8 9 10 LNode *GetElem (LinkList L,int i) { int j=1 ; LNode *p = L-> next; if (i == 0 )return L; if (i<0 )return NULL ; while (p&&j<i){ p=p->next;j++; } return p; }
按值查找表结点O(n) 1 2 3 4 5 6 LNode *LocateElem (LinkList L, ElemType e) { LNode *p = L-> next; while (p != NULL &&p-> data != e) p=p->next; return p; }
题1.从一个具有n个结点的单链表中查找其值等于x的结点时,在查找成功的情况下,需比较()个元素结点
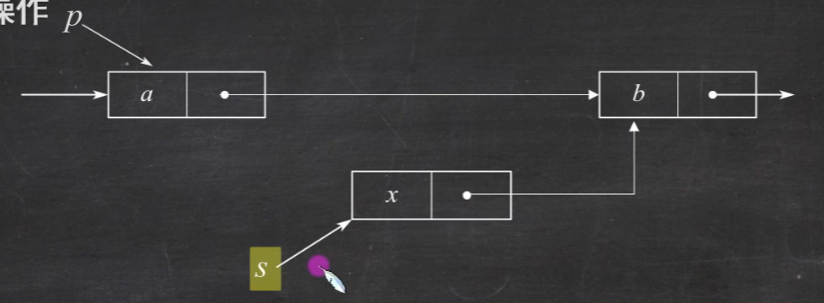
插入结点 先按位查找p=GetElem(L,i-1)
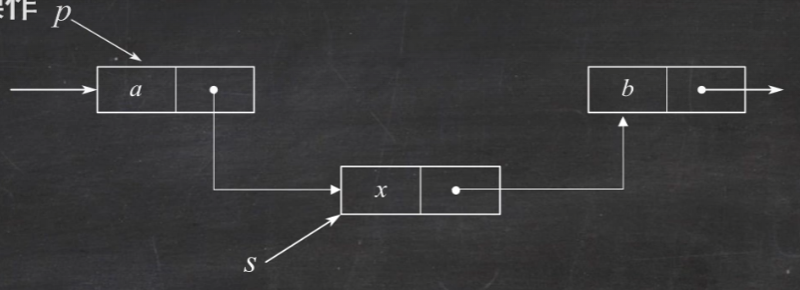
删除结点 先按位查找p=GetElem(L,i-1);
循环单链表 L->next=L
5.栈和队列 栈:先进后出
实训 题目1:顺序栈的基本操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 本关任务:对于顺序存储的字符栈完成三个操作函数,分别实现顺序栈的初始化,数据的入栈和出栈功能。 相关知识 实训中的类型定义及子函数的作用如下: (1)定义顺序栈类型SqStack; typedef struct { SElemType *base; SElemType *top; int stacksize; }SqStack; (2)子函数InitSqStack(SqStack &st),实现顺序栈的初始化; (3)子函数Push(SqStack &st, char e),实现顺序栈中的入栈运算; (4)子函数Pop(SqStack &st, char &e),实现顺序栈中的出栈运算; (5)主函数,在主函数中调用上述子函数,输出相应的结果。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 #include <iostream> using namespace std;#define MAXSIZE 10 #define OVERFLOW -2 typedef char SElemType;typedef struct { SElemType *base; SElemType *top; int stacksize; }SqStack; void InitStack (SqStack &S) S.base=new SElemType[MAXSIZE]; S.top=S.base; S.stacksize=MAXSIZE; } int Push (SqStack &S,SElemType e) if (S.top-S.base==S.stacksize)return 1 ; *S.top=e; S.top++; return 0 ; } int Pop (SqStack &S,SElemType &e) if (S.top==S.base)return 1 ; --S.top; e=*S.top; return 0 ; } int main () SqStack st; char e,a[MAXSIZE];int n; InitStack (st); cin>>n; for (int i=0 ;i<n;i++) cin>>a[i]; for (int j=0 ;j<n;j++) Push (st,a[j]); for (int k=0 ;st.top!=st.base;k++) { Pop (st,e); cout<<e<<" " ; } return 0 ; }
题目2:顺序队列的基本操作 题目:
1 2 3 4 5 6 7 8 9 10 11 12 13 本关任务:对于顺序存储的字符队列完成两个操作函数,分别实现顺序循环队列的的入队和出队功能。 相关知识 (1)定义循环队列类型SqQueue; typedef struct { QElemType *base; int front; int rear; }SqQueue; (2)子函数InitQueue(SqQueue &sq),实现循环队列的初始化; (3)子函数EnQueue(SqQueue &sq,char x),实现循环队列中的入队运算; (4)子函数DeQueue(SqQueue &sq,char &x),实现循环队列中的出队运算; (5)编写主函数,在主函数中调用上述子函数,输出相应的结果。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <iostream> using namespace std;#define MAXSIZE 10 #define OVERFLOW -2 typedef char QElemType;typedef struct { QElemType *base; int front; int rear; }SqQueue; void InitQueue (SqQueue &Q) Q.base=new QElemType[MAXSIZE]; Q.front=Q.rear=0 ; } int EnQueue (SqQueue &Q,QElemType e) if ((Q.rear+1 )%MAXSIZE==Q.front)return 1 ; Q.base[Q.rear]=e; Q.rear=(Q.rear+1 )%MAXSIZE; return 0 ; } int DeQueue (SqQueue &Q,QElemType &e) if (Q.front==Q.rear)return 1 ; e=Q.base[Q.front]; Q.front=(Q.front+1 )%MAXSIZE; return 0 ; } int main () SqQueue queues; InitQueue (queues); char a; int n; cin>>n; for (int i=0 ;i<n;i++) { cin>>a; EnQueue (queues,a); } for (int i=0 ;i<n;i++) { DeQueue (queues,a); cout<<a<<" " ; } }
题目3:用栈实现进制转换 题目:
1 2 3 4 5 6 7 8 9 10 11 12 13 本关任务:编写一个程序,实现对于任意一个非负十进制数,打印输出与其等值的八进制数。 相关知识 算法基本思想: 当将一个十进制整数N转换为八进制数时,在计算过程中,把N与8求余得到的八进制数的各位依次进栈,计算完毕后将栈中的八进制数依次出栈输出,输出结果就是待求得的八进制数。 算法描述: ①初始化一个空栈S。 ②当十进制数N非零时,循环执行以下操作: ●把N与8求余得到的八进制数压入栈S; ● N更新为N与8的商。 ③当栈S非空时,循环执行以下操作: ●弹出栈顶元素e; ●输出e。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> using namespace std;#define MAXSIZE 10 #define OVERFLOW -2 typedef int SElemType;typedef struct { SElemType *base; SElemType *top; int stacksize; }SqStack; void InitStack (SqStack &S) S.base=new SElemType[MAXSIZE]; S.top=S.base; S.stacksize=MAXSIZE; } int Push (SqStack &S,SElemType &e) if (S.top-S.base==S.stacksize)return OVERFLOW; *S.top=e; S.top++; return 0 ; } int Pop (SqStack &S,SElemType &e) if (S.top==S.base)return 1 ; --S.top; e=*S.top; return 0 ; } int main () SqStack stk; InitStack (stk); int n,e,s; cin>>n; while (n!=0 ) { s=n%8 ; Push (stk,s); n=n/8 ; } for (int i=0 ;stk.top!=stk.base;i++) { Pop (stk,e); cout<<e; } }
题1.向顺序栈中压入新元素,应当()
6.树、二叉树 树:n个结点的有限集
树的性质: 1、树中结点树等于所有结点的度数+1
题3.设一棵度为3的树中有2个度数为1的结点,2个度数为2的结点,2个度数为3
二叉树 满二叉树:二叉树结点都是满的
性质1:非空二叉树上的叶子结点数等于度为2的结点数加1,即n0=n2+1
题2.将一棵有100个结点的完全二叉树,从根这一层开始,每一层从左到右依次
二叉树存储结构 (1)顺序存储结构:指用一组地址连续的存储单元依次自上而下、自左至右存储完全二叉树的结点元素,即将完全二叉树上编号为i的结点元素存储在一维数组下标i-1的分量中
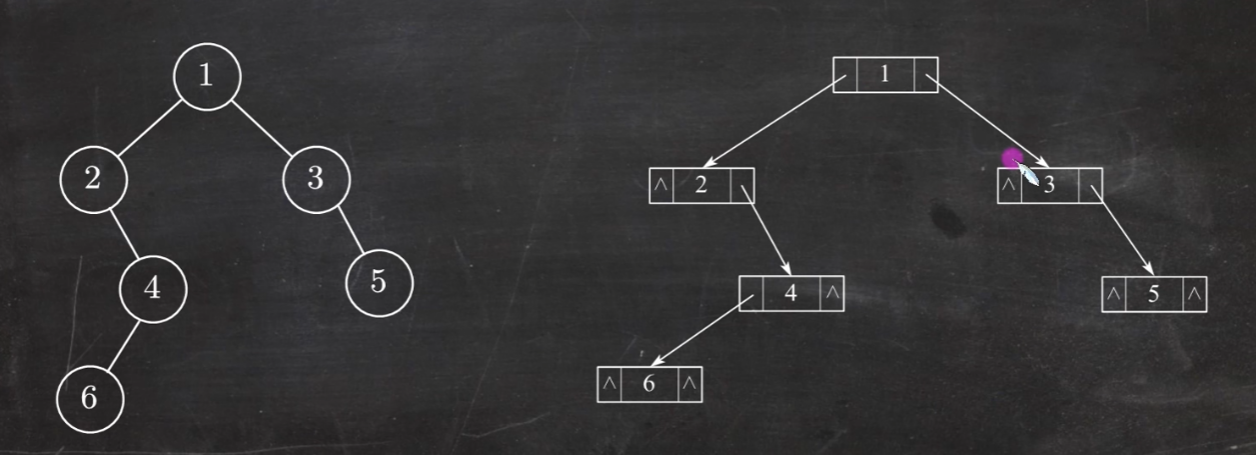
1 2 3 4 typedef struct BiTNode {ElemType data; struct BiTNode *Ichild , *rchild ;} BiTNode, *BiTree;
二叉树的遍历 原则:先左子树再右子树
1 2 3 4 5 6 7 void PreOrder (BiTree T) { if (T != NULL ) { visit(T); PreOrder(T->Ichild); PreOrder(T->rchild) ; } }
中序遍历:左、根、右
1 2 3 4 5 6 7 void InOrder (BiTree T) { if (T != NULL ) { InOrder (T->Ichild) ; visit(T); InOrder (T->rchild) ; } }
后序遍历:右、根、左
1 2 3 4 5 6 7 void PostOrder (BiTree T) { if (T != NULL ) { PostOrder (T->Ichild); PostOrder (T->rchild) ; visit(T); } }
层次遍历——队列
1 2 3 4 5 6 7 8 9 10 11 12 13 void LevelOrder (BiTree T) { InitQueue (Q) ; BiTNode *p=T; EnQueue (Q, p) ; while (!IsEmpty (Q)) { DeQueue (Q, p) ; visit(p); if (p->Ichild != NULL ) EnQueue (Q, p->Ichild); if (p->rchild != NULL ) EnQueue(Q,p->rchild); } }
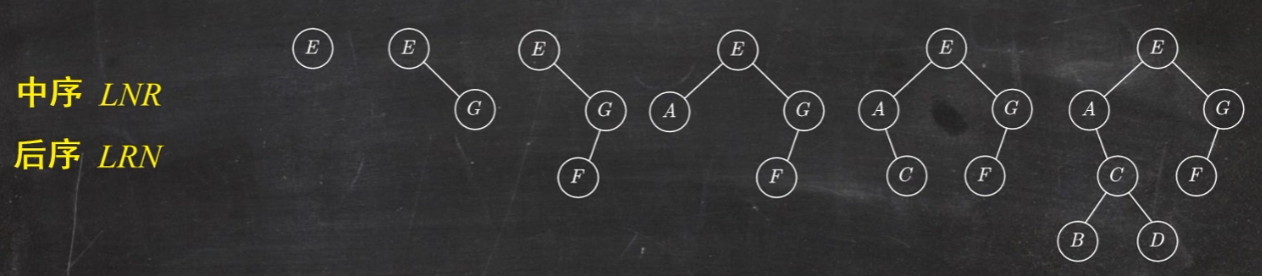
题1.已知一棵二叉树的先序遍历结果为ABCDEF,中序遍历结果为 CBAEDF,
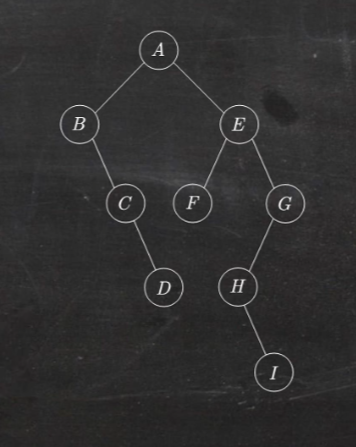
题2.某二叉树结点的中序序列为:ABCDEFG,后序序列为:BDCAFGE,则其根结点
实训 题目1
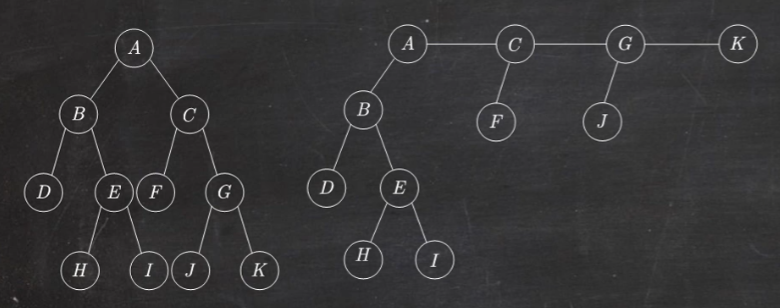
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 本关任务:编写一个程序,先由先序遍历序列建立一棵二叉树,再分别实现二叉树先序、中序、后序遍历的递归算法,最后利用后序遍历方法实现求解二叉树深度的操作。 相关知识 为了完成本关任务,你需要掌握:1. 如何由先序遍历序列建立一棵二叉树,2. 如何使用递归算法实现遍历。 由先序遍历序列建立一棵二叉树 如图所示二叉树,输入先序序列为: ABC##DE#G##F### 采用以下函数实现二叉树的二叉链表结构创建 void CreateBiTree (BiTree &T) { char ch; cin >> ch; if (ch=='#' ) T=NULL ; else { T=new BiTNode; T->data=ch; CreateBiTree(T->lchild); CreateBiTree(T->rchild); } }
答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #include <iostream> using namespace std; typedef struct BiNode { char data; struct BiNode *lchild,*rchild; }BiTNode,*BiTree; void CreateBiTree (BiTree &T) char ch; cin >> ch; if (ch=='#' ) T=NULL ; else { T=new BiTNode; T->data=ch; CreateBiTree (T->lchild); CreateBiTree (T->rchild); } } void PreOrderTraverse (BiTree T) if (T) { cout<<T->data; PreOrderTraverse (T->lchild); PreOrderTraverse (T->rchild); } } void InOrderTraverse (BiTree T) if (T) { InOrderTraverse (T->lchild); cout<<T->data; InOrderTraverse (T->rchild); } } void postOrderTraverse (BiTree T) if (T) { postOrderTraverse (T->lchild); postOrderTraverse (T->rchild); cout<<T->data; } } int Depth (BiTree T) int dep1=0 ,dep2=0 ; if (T) { dep1=Depth (T->lchild); dep2=Depth (T->rchild); if (dep1>dep2)return (dep1+1 ); else return (dep2+1 ); } else return 0 ; } int main () BiTree tree; CreateBiTree (tree); cout<<"先序序列:" ; PreOrderTraverse (tree); cout<<endl; cout<<"中序序列:" ; InOrderTraverse (tree); cout<<endl; cout<<"后序序列:" ; postOrderTraverse (tree); cout<<endl; cout<<"二叉树的深度:" ; cout<<Depth (tree); return 0 ; }
题目2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 本关任务:编写一个程序,实现用二叉树表示算术表达式,通过对二叉树的遍历,中缀表达式的输出。 相关知识 为了完成本关任务,你需要掌握:1. 如何用二叉树表示算术表达式,2. 如何正确输出中缀表达式。 用二叉树表示算术表达式 一个算术表达式可以用二叉树表示,这个二叉树有2 个特点: 1. 叶子结点一定是操作数2. 分支结点一定是运算符一棵二叉树可以转换为等价的中缀表达式,并且为了反映运算符的计算次序应该适当加上括号。 如图所示二叉树转换为等价的中缀表达式为: a + b * (c – d) – e / f 输出中缀表达式 一个算术表达式可以用二叉树表示,这个二叉树的中序遍历序列加上必要的括号即为中缀表达式,在中序遍历二叉树的过程中,如果当前访问的是叶子结点,则无需加括号,可以直接输出。如果当前访问的结点深度大于1 ,则对左子树递归调用之前要加上左括号,对右子树递归调用之后要加上右括号。 算法基本思想: 输入:二叉链表根指针T,二叉树的深度deep 输出:中缀表达式 1. 若指针T为空,则算法结束;2. 否则执行下述操作:2.1 若deep>1 ,则输出左括号;2.2 deep++;递归调用左子树;2.3 输出T->data;2.4 deep++;递归转换右子树;2.5 若deep>1 ,则输出右括号;
答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> using namespace std; typedef struct BiNode { char data; struct BiNode *lchild,*rchild; }BiTNode,*BiTree; void CreateBiTree (BiTree &T) char ch; cin >> ch; if (ch=='#' ) T=NULL ; else { T=new BiTNode; T->data=ch; CreateBiTree (T->lchild); CreateBiTree (T->rchild); } } void InExpression (BiTree T, int depth = 1 ) if (T) { if ((T->lchild or T->rchild) and depth>1 )cout<<"(" ; InExpression (T->lchild,depth+1 ); cout<<T->data; InExpression (T->rchild,depth+1 ); if ((T->lchild or T->rchild) and depth>1 )cout<<")" ; } } int main () BiTree tree; CreateBiTree (tree); cout << "中缀表达式结果:" ; InExpression (tree); cout << endl; return 0 ; }
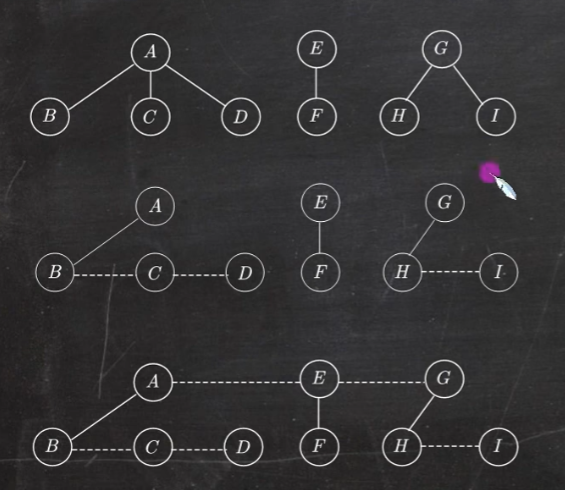
树和森林 树的存储结构:双亲表示法、孩子表示法、孩子兄弟表示法
森林转换成二叉树的画法:(左孩子右兄弟)
二叉树转化为森林就是反过来做上面的三个步骤
哈夫曼树 权:树中结点常被赋予一个代表某种意义的数值
题1.有一电文使用五种字符a,b,c,d,e,其出现频率依次为4,7,5,2,9
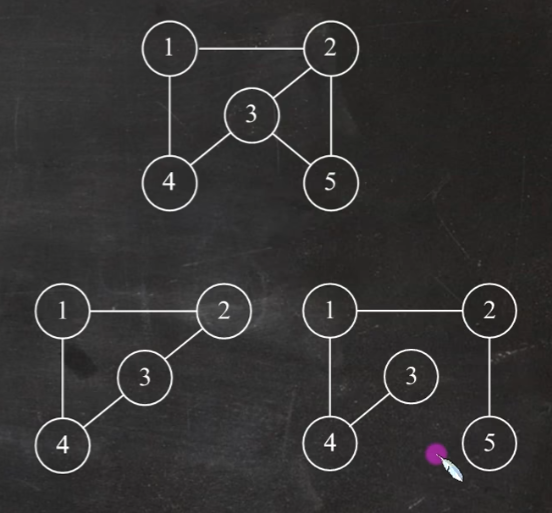
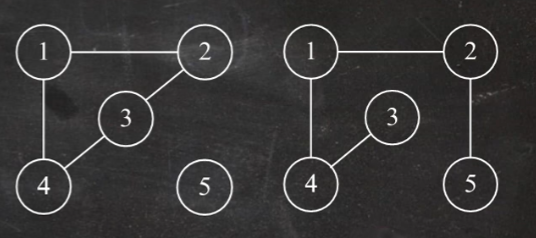
7.图 有向图:每条边都有方向<v,w>这个表示v到w的一条有向边
顶点的度 无向图:一个顶点有几条线就有多少度,无向图的全部顶点的度的和等于边数的两倍
边的权和网 每条边加入数值,相当于就是权值,有权值就叫带权图/网
路径、回路
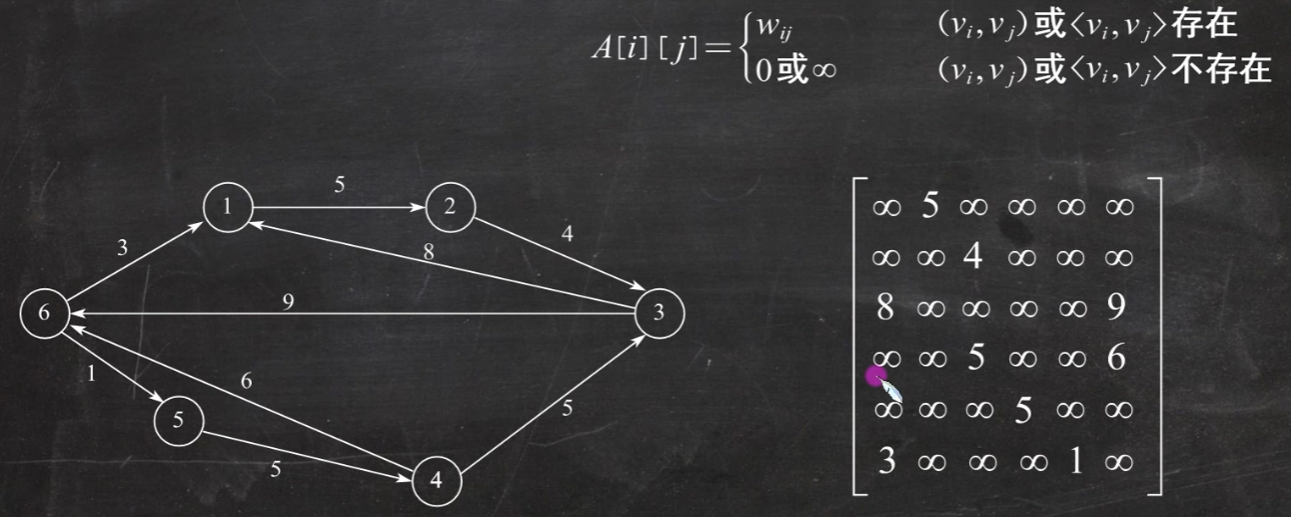
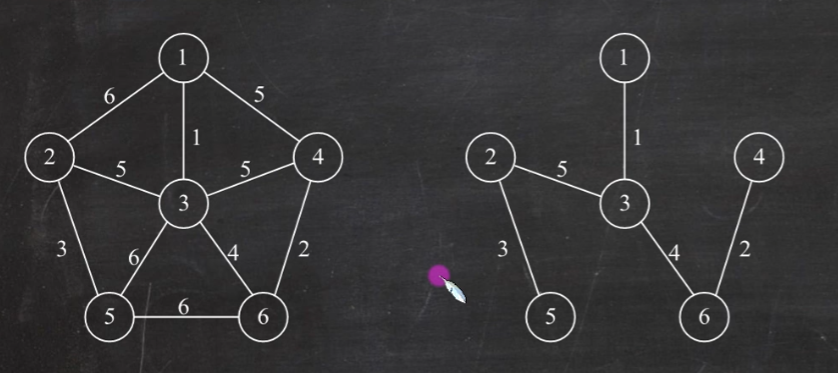
图的存储结构 邻接矩阵法
使用邻接矩阵存储方法:
题1. n个顶点的无向连通图用邻接矩阵表示时,该矩阵至少有()个非零元素
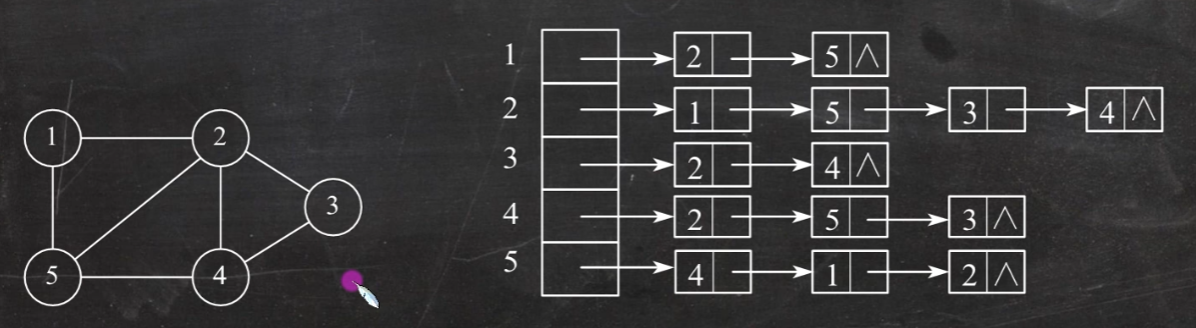
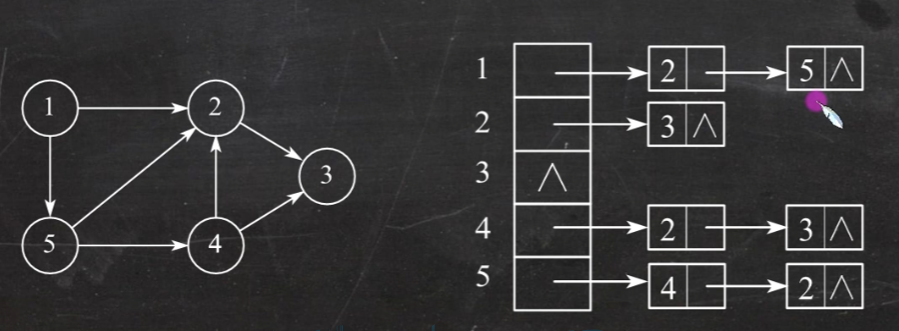
邻接表法
优点:
若G为无向图,则所需的存储空间为O(|V|+2|E|)
题5.在有向图的邻接表表示中,下面()最费时间
图的遍历 图的遍历:从图中的某一顶点出发,按照某种搜索方法沿着图中的所有顶点访问一次且仅访问一次
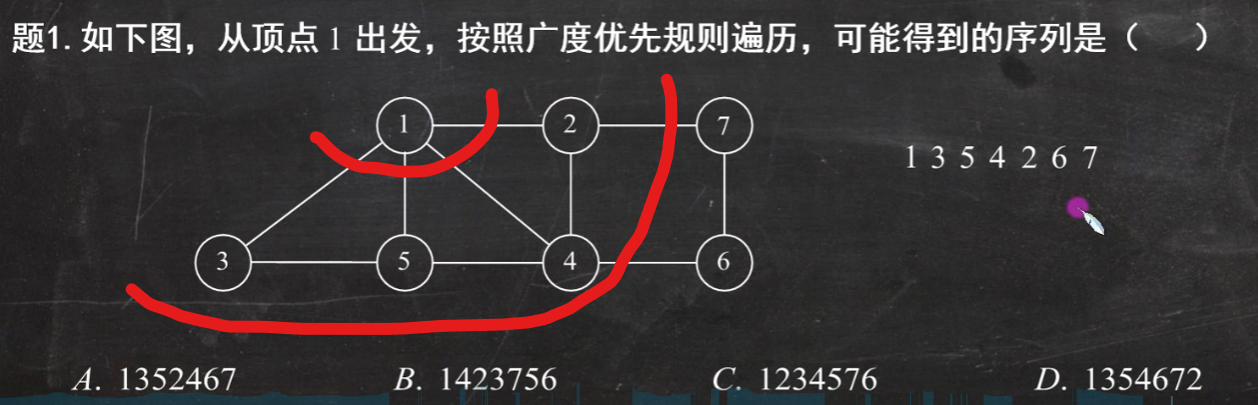
(1)广度优先搜索(bfs) 类似于二叉树的层序遍历算法
(2)深度优先搜索(dfs) 类似于树的先序遍历
图的应用 最小生成树 带权连通无向图中所有生成树中权值最小的生成树
Prim算法: 1、任取一顶点,去掉所有边
Kruskal 算法: 1、去掉所有边
最短路径 dijkstra算法
拓扑排序 AOV网:顶点表示活动<Vi,Vj>
8.查找 (1)查找 在数据集合中,寻找满足某种条件的数据元素的过程
顺序查找 从头开始一个一个找,找到就返回,没找到就返回失败
实训 题目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 本关任务:编写程序,实现顺序表上的顺序查找。 相关知识 实训中的类型定义及子函数的作用如下: (1 )定义顺序表中数据元素类型; typedef int ElemType;typedef int KeyType;typedef struct { KeyType key; ElemType data; } SqType; (2 )子函数Create_SSTable(SqType R[]) ,实现查找表的创建,从键盘上依次输入整型数据元素,创建查找表; (3 )子函数SqSearch(SqType R[],int n,KeyType k),实现顺序查找; (4 )子函数Show_End(int result,int testkey),输出查找的结果; (5 )主函数,在主函数中调用上述子函数,输出相应的结果。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <iostream> using namespace std ; #define MAXSIZE 8 #define OK 1; typedef int ElemType;typedef int KeyType;typedef struct { KeyType key; ElemType data; } SqType; int Create_SSTable (SqType R[]) { for (int i=0 ;i<MAXSIZE;i++) { cin >>R[i].key;} return 1 ; } int SqSearch (SqType R[],int n,KeyType k) { for (int i=0 ;i<MAXSIZE;i++) { if (R[i].key==k)return i+1 ; } return 0 ; } void Show_End (int result,int testkey) { if (result==0 ) cout <<"未找到" <<testkey<<endl ; else cout <<"找到" <<testkey<<"位置为" <<result<<endl ; } int main () { SqType R[MAXSIZE]; Create_SSTable(R); int n=sizeof (R)/sizeof (R[0 ]); int testkey1,testkey2,result; cin >>testkey1; result=SqSearch(R,n,testkey1); Show_End(result,testkey1); cin >>testkey2; result=SqSearch(R,n,testkey2); Show_End(result,testkey2); return 0 ; }
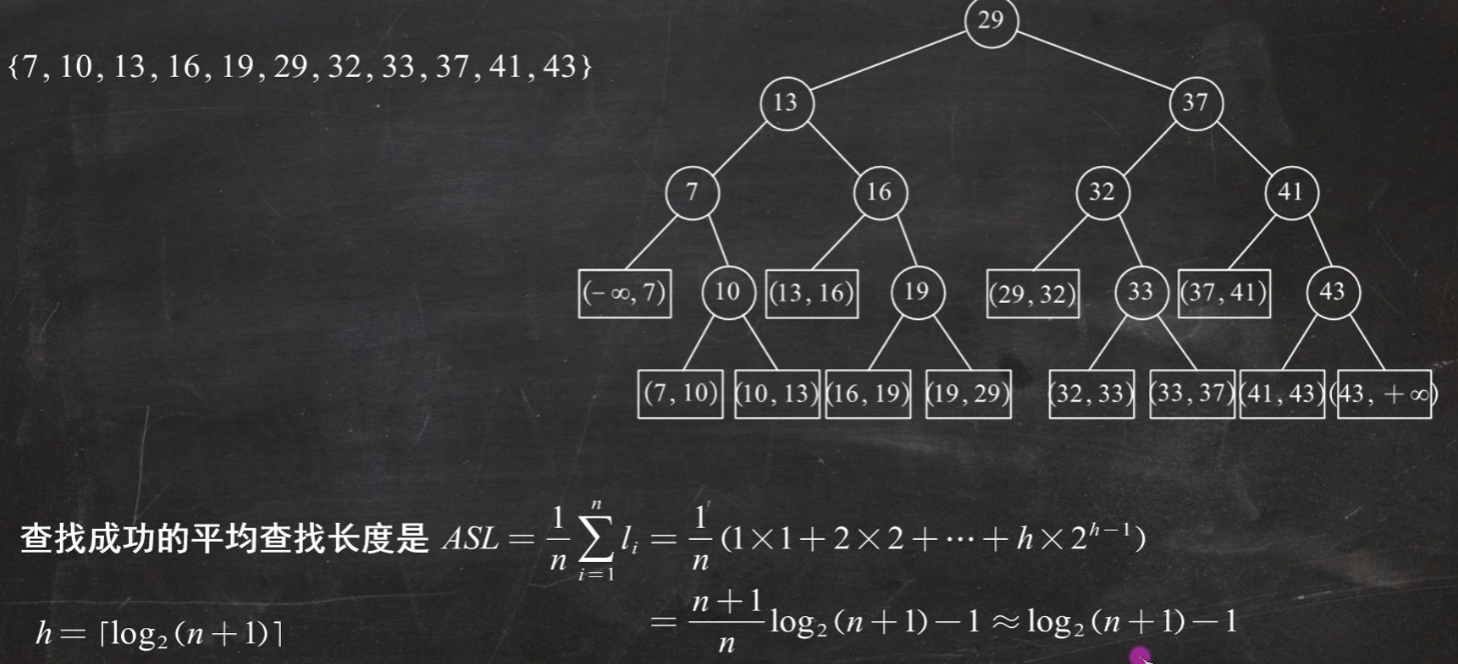
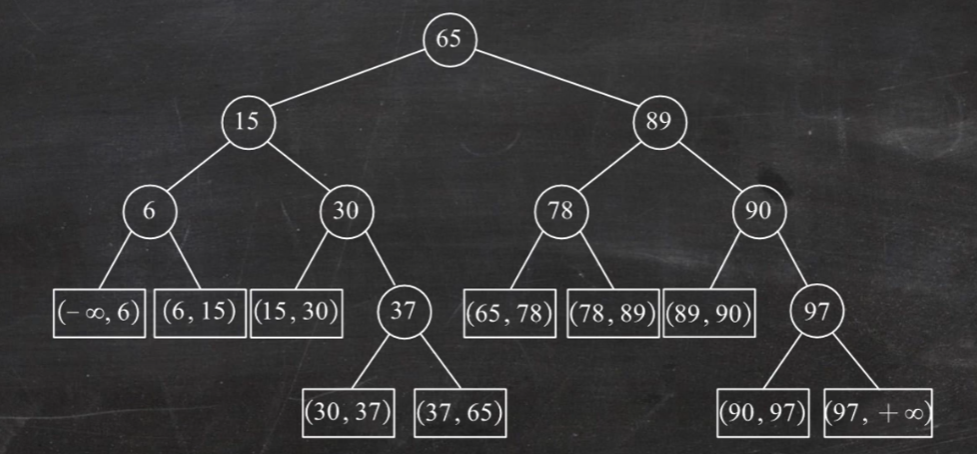
折半查找(二分查找) 仅适用于有序的顺序表
实训 题目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 本关任务:编写程序,实现有序顺序表上的折半查找。 相关知识 实训中的类型定义及子函数的作用如下: (1 )定义顺序表中数据元素类型; typedef int ElemType;typedef int KeyType;typedef struct { KeyType key; ElemType data; } SqType; (2 )子函数Create_SSTable(SqType R[]) ,实现查找表的创建,从键盘上依次输入有序的整型数据元素,创建查找表; (3 )子函数BinSearch(SqType R[],int n,KeyType k),实现折半查找; (4 )子函数Show_End(int result,int testkey),输出查找的结果; (5 )主函数,在主函数中调用上述子函数,输出相应的结果。
答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> using namespace std;#define MAXSIZE 8 #define OK 1; typedef int ElemType;typedef int KeyType;typedef struct { KeyType key; ElemType data; } SqType; int Create_SSTable (SqType R[]) for (int i=0 ;i<MAXSIZE;i++) {cin>>R[i].key; } return 1 ; } int BinSearch (SqType R[],int n,KeyType k) int low=0 ,high=n-1 ,mid; while (low<=high) { mid=(low+high)/2 ; if (R[mid].key==k)return mid+1 ; else if (R[mid].key>k)high=mid-1 ; else low=mid+1 ; } return 0 ; } void Show_End (int result,int testkey) if (result==0 ) cout<<"未找到" <<testkey<<endl; else cout<<"找到" <<testkey<<"位置为" <<result<<endl; } int main () SqType R[MAXSIZE]; Create_SSTable (R); int n=sizeof (R)/sizeof (R[0 ]); int testkey1,testkey2,result; cin>>testkey1; result=BinSearch (R,n,testkey1); Show_End (result,testkey1); cin>>testkey2; result=BinSearch (R,n,testkey2); Show_End (result,testkey2); return 0 ; }
散列表 散列函数: $Hash(key) = Addr$
by 梁家诺