1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
| import ipaddress
def parse_rule(line):
"""
解析单条规则行,返回元组 (action, proto, src, dst, dport)。
src 和 dst 如果是 CIDR,会转换为 (ip_network, prefix) 用于匹配。
""" parts = line.split()
action = parts[0]
proto = parts[1]
src = parts[2]
dst = parts[3]
dport = parts[4]
if src != 'any' and '/' in src:
src = ipaddress.IPv4Network(src, strict=False)
if dst != 'any' and '/' in dst:
dst = ipaddress.IPv4Network(dst, strict=False)
return (action, proto, src, dst, dport)
def parse_traffic(line):
"""
解析单条流量行,返回元组 (proto, src, dst, dport)。
src 和 dst 是字符串形式的 IPv4 地址。
""" parts = line.split()
proto = parts[0]
src = parts[1]
dst = parts[2]
dport = parts[3]
return (proto, src, dst, dport)
def match_rule(rule, traffic):
"""
检查流量是否匹配单条规则。
规则和流量都是元组形式。 返回 True 如果匹配,否则 False。
""" _, rule_proto, rule_src, rule_dst, rule_dport = rule
traffic_proto, traffic_src, traffic_dst, traffic_dport = traffic
return False
return False
if isinstance(rule_src, ipaddress.IPv4Network):
try:
ip = ipaddress.IPv4Address(traffic_src)
if ip not in rule_src:
return False
except:
return False
else:
if rule_src != traffic_src:
return False
if isinstance(rule_dst, ipaddress.IPv4Network):
try:
ip = ipaddress.IPv4Address(traffic_dst)
if ip not in rule_dst:
return False
except:
return False
else:
if rule_dst != traffic_dst:
return False
return True
def main():
with open('rules.txt', 'r') as f:
rule_lines = f.read().splitlines()
rules = [parse_rule(line) for line in rule_lines]
with open('traffic.txt', 'r') as f:
traffic_lines = f.read().splitlines()
traffic_list = [parse_traffic(line) for line in traffic_lines]
allow_count = 0
for traffic in traffic_list:
matched = False
for rule in rules:
if match_rule(rule, traffic):
if action == 'allow':
allow_count += 1
matched = True
break
if not matched:
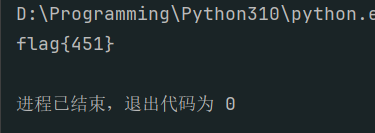
print(f"flag{{{allow_count}}}")
if __name__ == "__main__":
main()
|