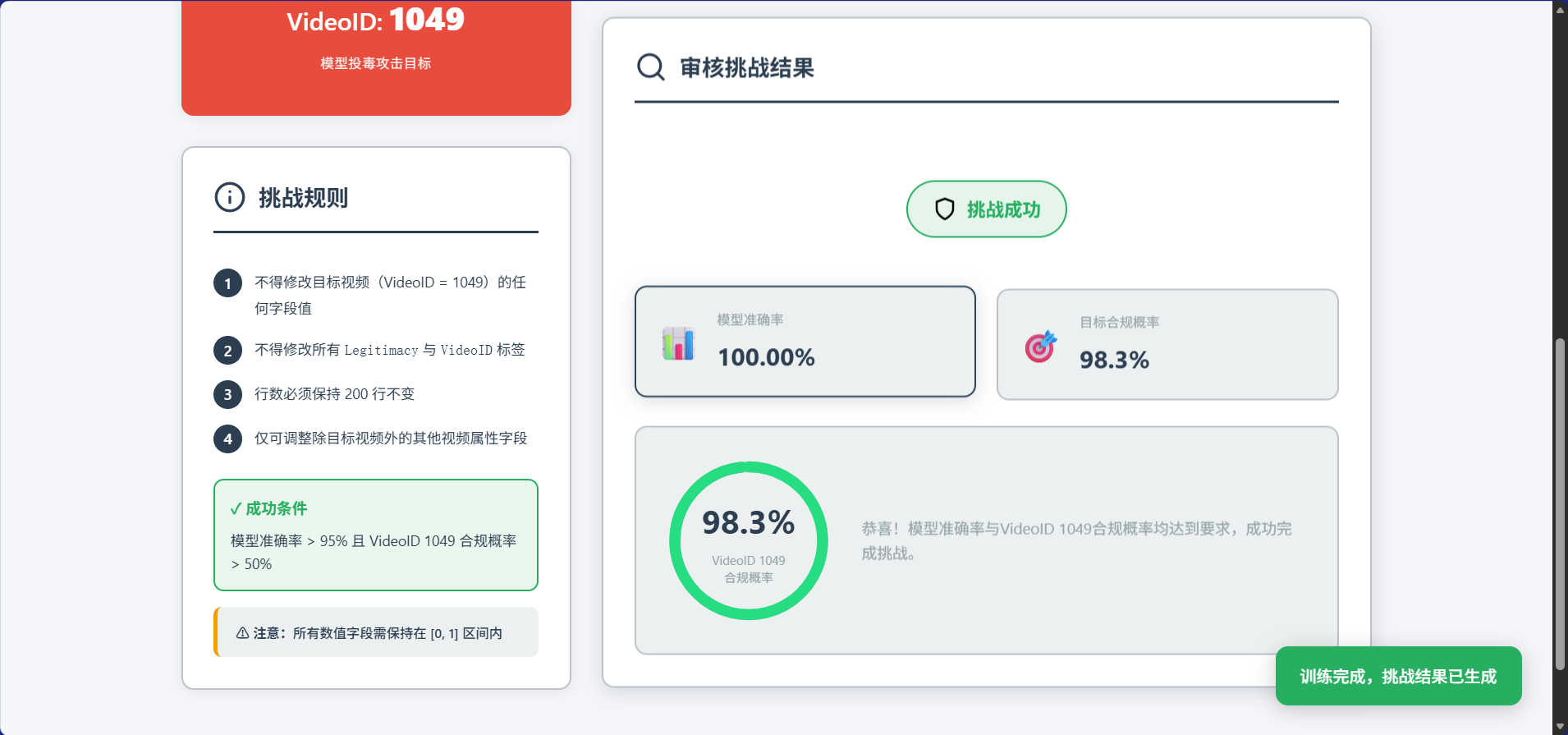
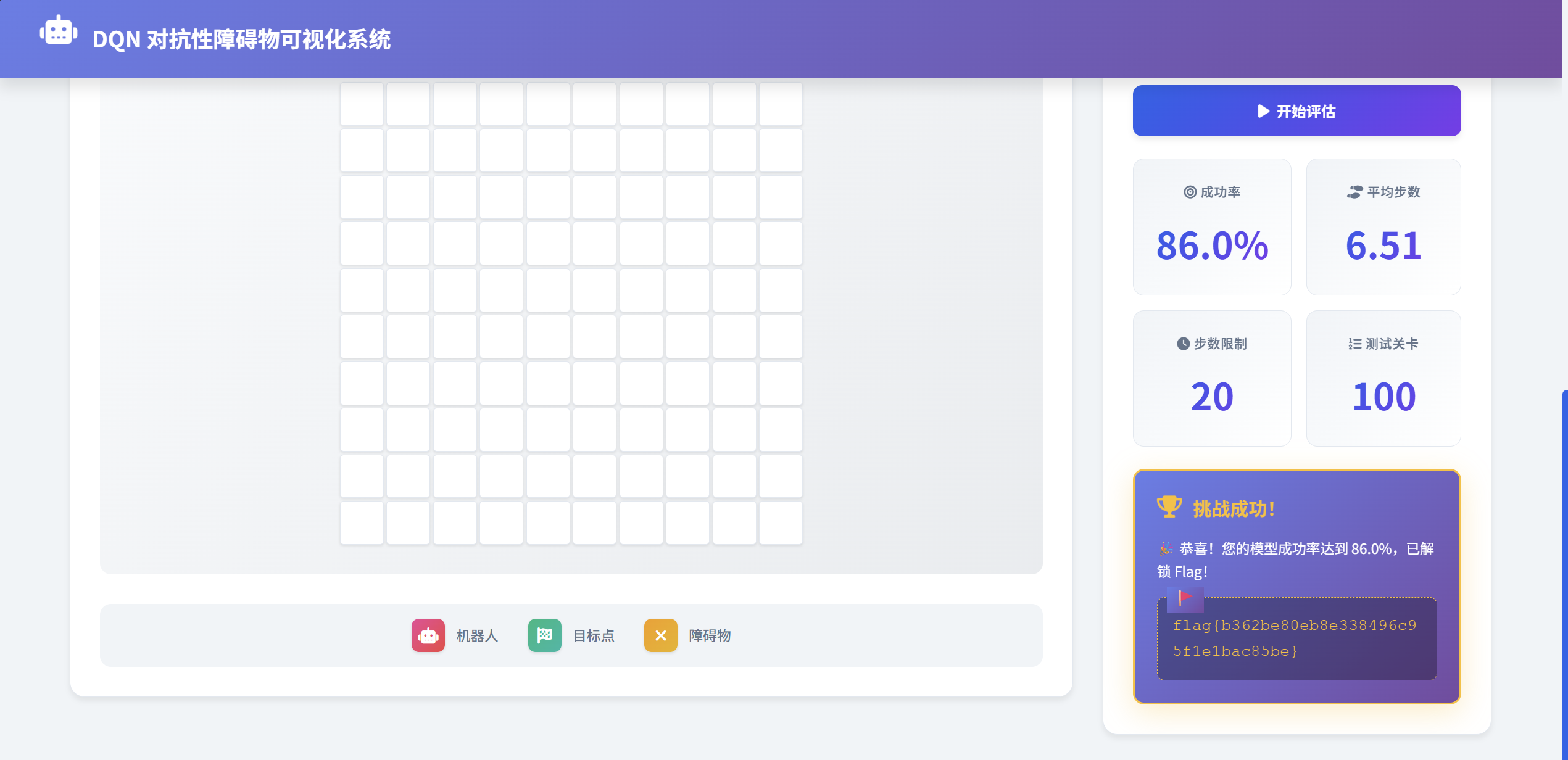
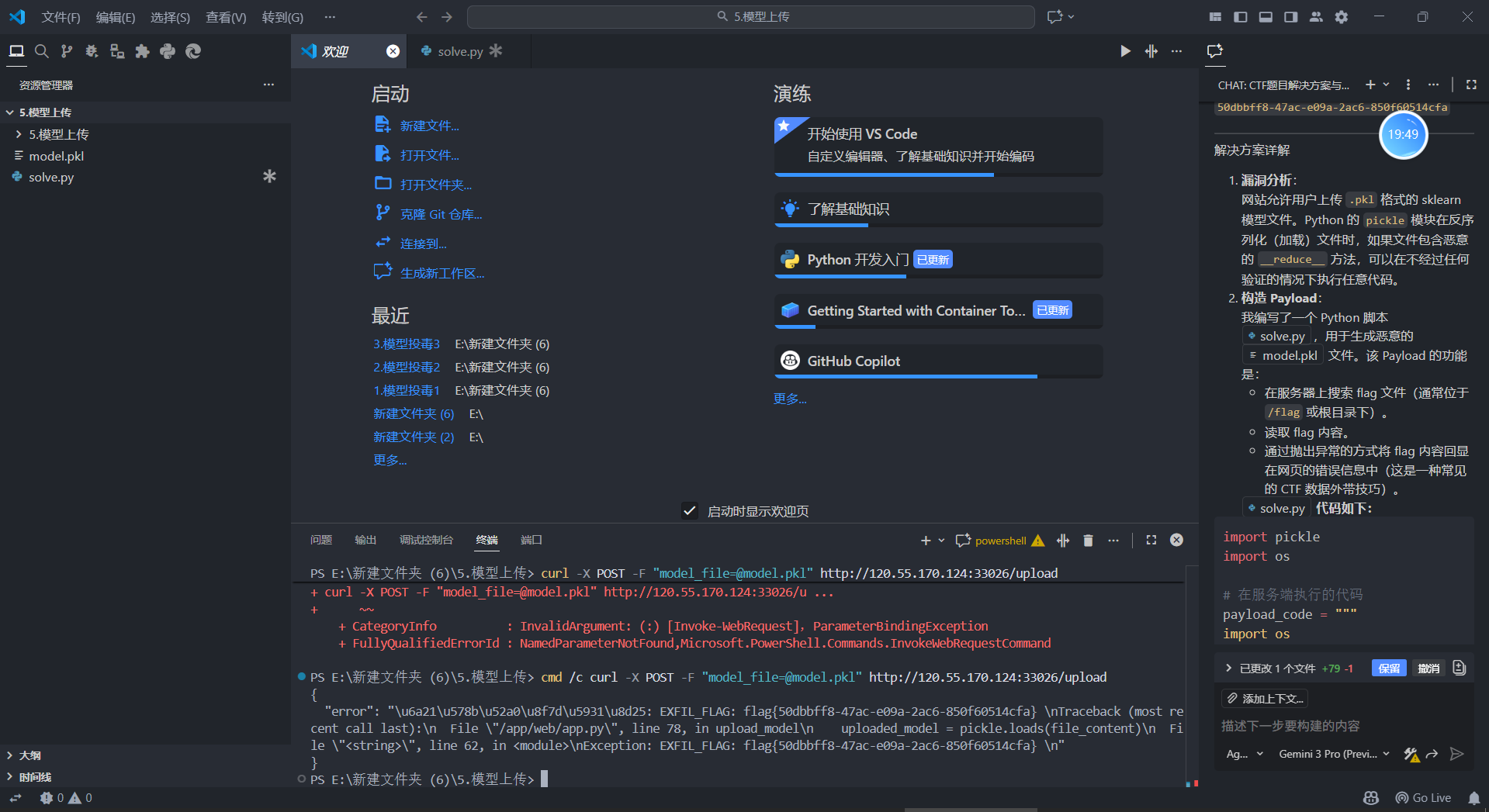
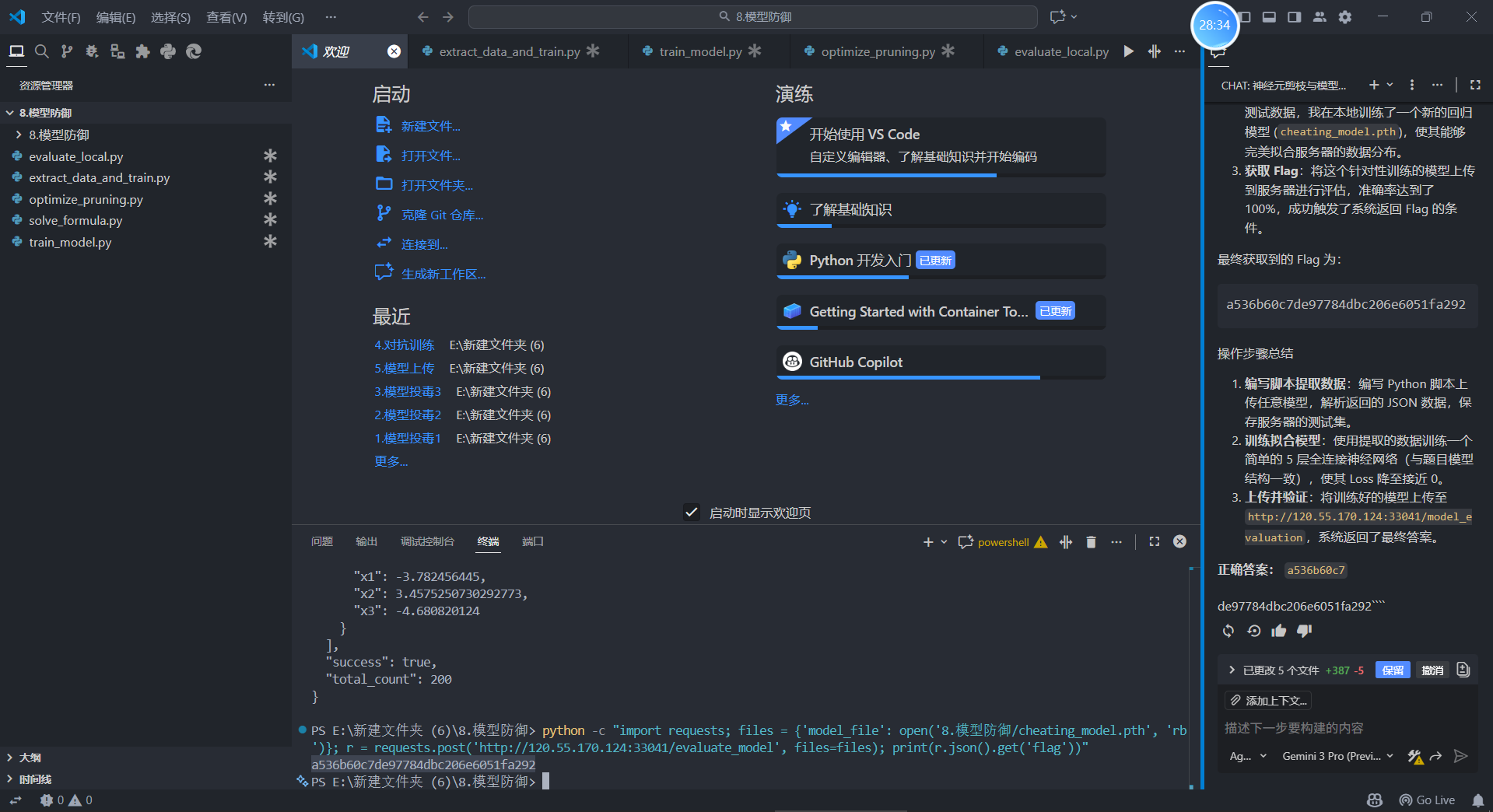
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
| import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
from robot_env import RobotGridEnv
from model import DQN
BATCH_SIZE = 128
LR = 0.0005
GAMMA = 0.99
EPSILON_START = 1.0
EPSILON_END = 0.01
EPSILON_DECAY = 0.999
TARGET_UPDATE = 20
MEMORY_CAPACITY = 50000
MAX_EPISODES = 10000
class Agent:
"""
DQN 智能体类
包含网络定义、动作选择、经验存储和模型更新逻辑
"""
def __init__(self, input_dim, output_dim):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.policy_net = DQN(input_dim, output_dim).to(self.device)
self.target_net = DQN(input_dim, output_dim).to(self.device)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
self.memory = deque(maxlen=MEMORY_CAPACITY)
self.epsilon = EPSILON_START
self.output_dim = output_dim
def select_action(self, state):
"""
根据当前状态选择动作
采用 Epsilon-Greedy 策略:以 epsilon 概率随机选择,以 1-epsilon 概率贪婪选择
"""
if random.random() < self.epsilon:
return random.randint(0, self.output_dim - 1)
else:
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
with torch.no_grad():
q_value = self.policy_net(state)
return q_value.argmax().item()
def store_transition(self, s, a, r, s_, done):
"""
将一条状态转移样本存储到经验回放池中
s: 当前状态
a: 执行的动作
r: 获得的奖励
s_: 下一状态
done: 是否结束
"""
self.memory.append((s, a, r, s_, done))
def learn(self):
"""
从经验池中采样并更新网络参数 (DQN 核心算法)
"""
if len(self.memory) < BATCH_SIZE:
return
batch = random.sample(self.memory, BATCH_SIZE)
state_batch = torch.FloatTensor(np.array([x[0] for x in batch])).to(self.device)
action_batch = torch.LongTensor([x[1] for x in batch]).unsqueeze(1).to(self.device)
reward_batch = torch.FloatTensor([x[2] for x in batch]).unsqueeze(1).to(self.device)
next_state_batch = torch.FloatTensor(np.array([x[3] for x in batch])).to(self.device)
done_batch = torch.FloatTensor([x[4] for x in batch]).unsqueeze(1).to(self.device)
q_eval = self.policy_net(state_batch).gather(1, action_batch)
with torch.no_grad():
next_actions = self.policy_net(next_state_batch).argmax(1).unsqueeze(1)
q_next = self.target_net(next_state_batch).gather(1, next_actions)
q_target = reward_batch + GAMMA * q_next * (1 - done_batch)
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.policy_net.parameters(), 1.0)
self.optimizer.step()
def update_epsilon(self):
"""
衰减随机探索概率 epsilon
"""
self.epsilon = max(EPSILON_END, self.epsilon * EPSILON_DECAY)
def train():
"""
主训练循环
"""
env = RobotGridEnv()
input_dim = env.observation_space.shape[0]
output_dim = env.action_space.n
agent = Agent(input_dim, output_dim)
print(f"环境初始化完成。输入维度: {input_dim}, 动作空间: {output_dim}")
print("开始训练...")
success_history = deque(maxlen=100)
best_success_rate = 0.0
for i_episode in range(MAX_EPISODES):
state = env.reset()
total_reward = 0
while True:
action = agent.select_action(state)
next_state, reward, done, info = env.step(action)
rx, ry = state[0], state[1]
tx, ty = state[2], state[3]
dist_old = np.sqrt((rx-tx)**2 + (ry-ty)**2)
nrx, nry = next_state[0], next_state[1]
dist_new = np.sqrt((nrx-tx)**2 + (nry-ty)**2)
if done and info.get('is_success', False):
reward = 200.0
elif abs(reward) < 50:
reward += 15.0 * (dist_old - dist_new)
if dist_new < 0.25:
reward += 50.0 * (dist_old - dist_new)
if dist_new < dist_old:
reward += 5.0
else:
reward -= 5.0
reward -= 1.0
for i in range(3):
ox, oy = next_state[4+2*i], next_state[5+2*i]
d_obs = np.sqrt((nrx-ox)**2 + (nry-oy)**2)
if d_obs < 0.2:
reward -= 1.5 * (0.2 - d_obs) / 0.2
real_done = done
if done and info.get('failure_reason') == 'timeout':
real_done = False
agent.store_transition(state, action, reward, next_state, real_done)
agent.learn()
total_reward += reward
state = next_state
if done:
is_success = info.get('is_success', False)
steps = env.current_step
real_success = is_success and (steps < 20)
success_history.append(1 if real_success else 0)
break
if i_episode % TARGET_UPDATE == 0:
agent.target_net.load_state_dict(agent.policy_net.state_dict())
agent.update_epsilon()
current_success_rate = sum(success_history) / len(success_history) if success_history else 0.0
if current_success_rate >= best_success_rate and len(success_history) >= 50:
best_success_rate = current_success_rate
torch.save(agent.policy_net.state_dict(), "dqn_weights.pth")
if i_episode % 10 == 0:
print(f"Episode: {i_episode}, Total Reward: {total_reward:.2f}, Epsilon: {agent.epsilon:.2f}, Success Rate (100 ep): {current_success_rate:.2f}")
print(f"训练结束,最佳成功率: {best_success_rate:.2f}")
if __name__ == "__main__":
train()
|